V4.0 水平拆分对于V2.0 V3.0方案遇到瓶颈时,都可以通过水平拆分来解决,水平拆分和垂直拆分有较大区别,垂直拆分拆完的结果,在一个实例上是拥有全量数据的,而水平拆分之 后,任何实例都只有全量的1/n的数据,以下图Userinfo的拆分为例,将userinfo拆分为3个cluster,每个cluster持有总量的 1/3数据,3个cluster数据的总和等于一份完整数据(注:这里不再叫单个实例 而是叫一个cluster 代表包含主从的一个小mysql集群)
数据如何路由?1.Range拆分sharding key按连续区间段路由,一般用在有严格自增ID需求的场景上,如Userid, Userid Range的小例子:以userid 3000W 为Range进行拆分 1号cluster userid 1-3000W 2号cluster userid 3001W-6000W 2.List拆分 List拆分与Range拆分思路一样,都是通过给不同的sharding key来路由到不同的cluster,但是具体方法有些不同,List主要用来做sharding key不是连续区间的序列落到一个cluster的情况,如以下场景:
业务希望能够把一个地区的所有数据组织到一起来搜索,这种场景List拆分可以轻松搞定 3.Hash拆分通过对sharding key 进行哈希的方式来进行拆分,常用的哈希方法有除余,字符串哈希等等,除余如按userid%n 的值来决定数据读写哪个cluster,其他哈希类算法这里就不细展开讲了。 数据拆分后引入的问题: 数据水平拆分引入的问题主要是只能通过sharding key来读写操作,例如以userid为sharding
key的切分例子,读userid的详细信息时,一定需要先知道userid,这样才能推算出再哪个cluster进而进行查询,假设我需要按
username进行检索用户信息,需要引入额外的反向索引机制(类似HBASE二级索引),如在redis上存储
username->userid的映射,以username查询的例子变成了先通过查询username->userid,再通过
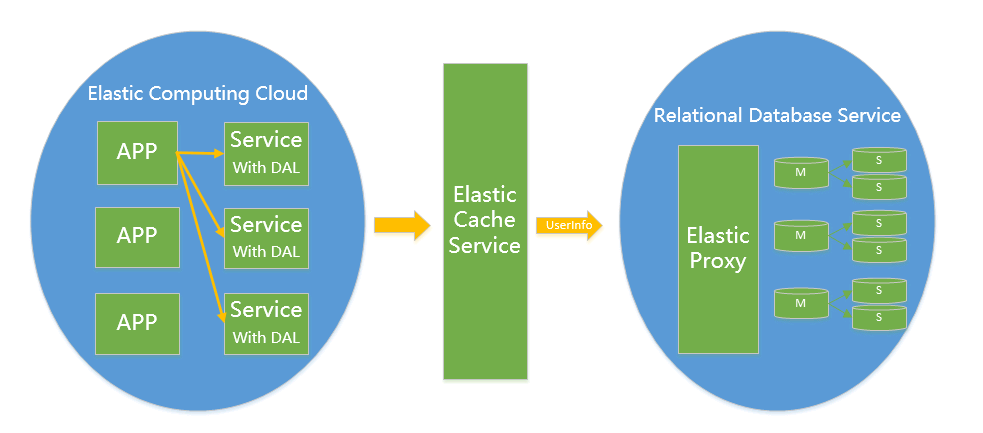
userid查询相应的信息。 在这样的架构下,我们来看看数据存储的瓶颈是什么? 有没有类似飞机空中加油的感觉,这是一个脏活,累活,容易出问题的活,为了避免这个,我们一般在最开始的时候,设计足够多的sharding cluster来防止可能的cluster扩容这件事情 V5.0 云计算 腾飞云计算现在是各大IT公司内部作为节约成本的一个突破口,对于数据存储的mysql来说,如何让其成为一个saas(Software as a Service)是关键点。在MS的官方文档中,把构建一个足够成熟的SAAS(MS简单列出了SAAS应用的4级成熟度)所面临的3个主要挑战:可配置性,可扩展性,多用户存储结构设计称为”three headed monster”. 可配置性和多用户存储结构设计在Mysql saas这个问题中并不是特别难办的一件事情,所以这里重点说一下可扩展性。 Mysql作为一个saas服务,在架构演变为V4.0之后,依赖良好的sharding key设计, 已经不再存在扩展性问题,只是他在面对扩容缩容时,有一些脏活需要干,而作为saas,并不能避免扩容缩容这个问题,所以只要能把V4.0的脏活变成 1. 扩容缩容对前端APP透明(业务代码不需要任何改动) 2.扩容缩容全自动化且对在线服务无影响 那么他就拿到了作为Saas的门票.
对于架构实现的关键点,需要满足对业务透明,扩容缩容对业务不需要任何改动,那么就必须eat our own
dog food,在你mysql
saas内部解决这个问题,一般的做法是我们需要引入一个Proxy,Proxy来解析sql协议,按sharding key 来寻找cluster,
判断是读操作还是写操作来请求主 或者 从,这一切内部的细节都由proxy来屏蔽。 |