写在最前: 本文主要描述在网站的不同的并发访问量级下,Mysql架构的演变 可扩展性 架构的可扩展性往往和并发是息息相关,没有并发的增长,也就没有必要做高可扩展性的架构,这里对可扩展性进行简单介绍一下,常用的扩展手段有以下两种 可扩展性的理想状态一个服务,当面临更高的并发的时候,能够通过简单增加机器来提升服务支撑的并发度,且增加机器过程中对线上服务无影响(no down time),这就是可扩展性的理想状态!
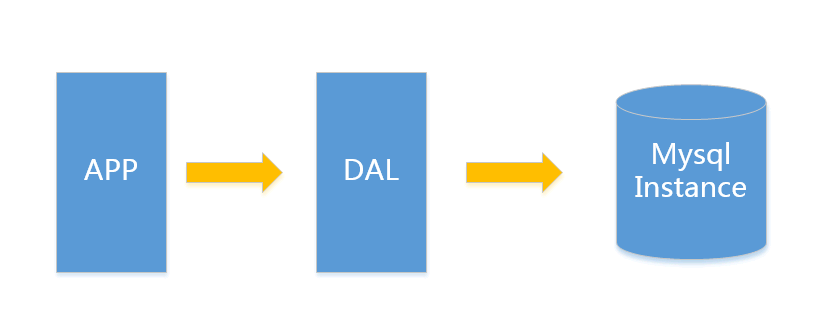
架构的演变V1.0 简单网站架构一个简单的小型网站或者应用背后的架构可以非常简单, 数据存储只需要一个mysql instance就能满足数据读取和写入需求(这里忽略掉了数据备份的实例),处于这个时间段的网站,一般会把所有的信息存到一个database instance里面。
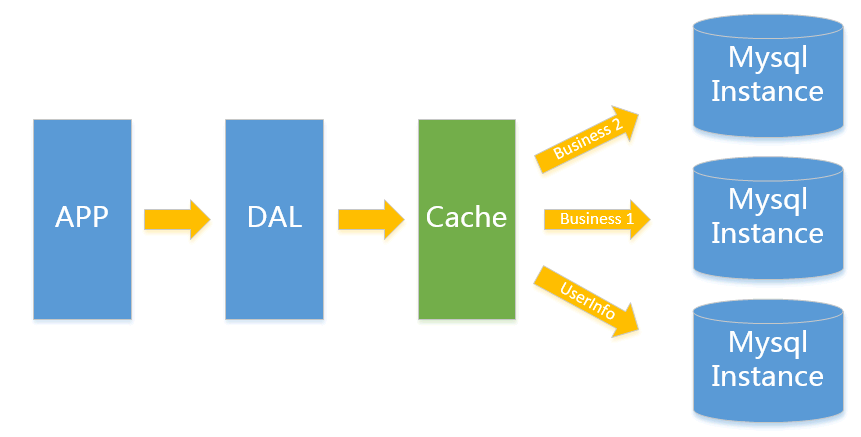
在这样的架构下,我们来看看数据存储的瓶颈是什么? 只有当以上3件事情任何一件或多件满足时,我们才需要考虑往下一级演变。 从此我们可以看出,事实上对于很多小公司小应用,这种架构已经足够满足他们的需求了,初期数据量的准确评估是杜绝过度设计很重要的一环,毕竟没有人愿意为不可能发生的事情而浪费自己的经历。 V2.0 垂直拆分一般当V1.0 遇到瓶颈时,首先最简便的拆分方法就是垂直拆分,何谓垂直?就是从业务角度来看,将关联性不强的数据拆分到不同的instance上,从而达到消除瓶颈的 目标。以图中的为例,将用户信息数据,和业务数据拆分到不同的三个实例上。对于重复读类型比较多的场景,我们还可以加一层cache,来减少对DB的压 力。
在这样的架构下,我们来看看数据存储的瓶颈是什么? 1.单实例单业务 依然存在V1.0所述瓶颈 遇到瓶颈时可以考虑往本文更高V版本升级, 若是读请求导致达到性能瓶颈可以考虑往V3.0升级, 其他瓶颈考虑往V4.0升级
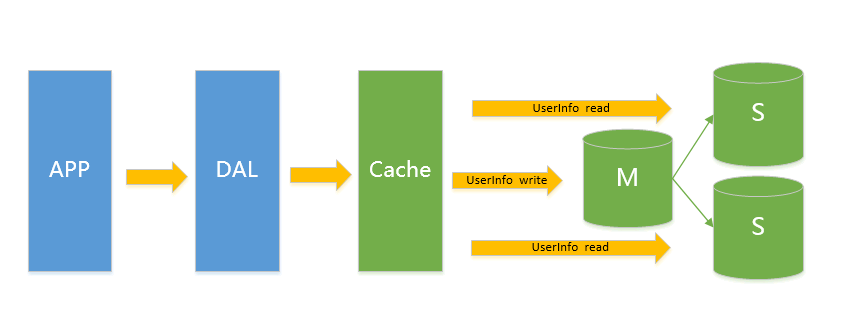
V3.0 主从架构此类架构主要解决V2.0架构下的读问题,通过给Instance挂数据实时备份的思路来迁移读取的压力,在Mysql的场景下就是通过主从结构,主库抗写压力,通过从库来分担读压力,对于写少读多的应用,V3.0主从架构完全能够胜任
在这样的架构下,我们来看看数据存储的瓶颈是什么?
|