学习使用开源工具将数据转换为有用信息
数据科学包括数学和计算机科学,是以从数据中提取价值为目的的。本文介绍了在这个快速发展领域中的数据科学和用于调查的突出开源工具。 PDF (291 KB)
数据科学的目标是从一组数据集中提取有用的信息。企业很久以前已经意识到了作为商业资产的数据的价值。但巨大的数据需要新的方法去理解和高效管理。越来越
多的工程师和科学家们正在构建运用数据科学来处理海量数据的系统。本文将向你介绍数据科学领域以及当今数据科学领域可用的开源工具。 数据科学与数据科学家
数据科学始于数据收集。收集的候选者可以是公开的数据或者来自内部商业处理的数据(例如,网站统计)。接下来是精炼:这是一个发挥创造性的过程,将数据减少至那些能回答专业问题的有用信息。比较典型的是,这些问题定义了提取信息的方法。在数据收集和精炼的步骤中,还有其它重要的方面,比如数据清洁(或预处理)和数据可视化。
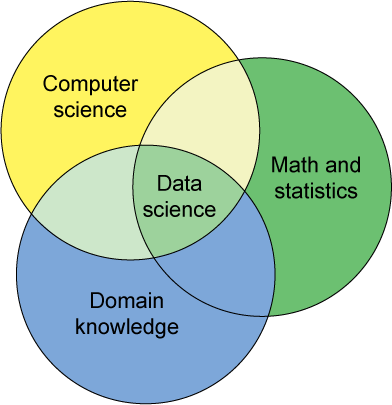
你也可以把数据科学看作是一个商业加工。O'Reilly的Mike Loukides通过一个非常有说服力的案例来说明数据科学不仅仅可以将数据转化为信息,还可以转化为产品。从这个角度看,这一领域就像是现代式的淘金——从如山的信息中争相搜索出有价值的金砖。 数据淘金方面的探索者被称为数据科学家。由于商务方面已经认识到自身数据的价值,所以对天才的多学科工程师和科学家的需求在增长。数据科学家一定具有计算 机科学、数学以及统计学方面的技术。理想情况下,他们还应当具有行业知识-对数据本身的理解(医疗行业、金融行业、互联网行业以及其它行业)。图1把数据 科学表示为计算机科学、数学和统计学以及行业知识的交集。
图1.数据科学涉及到的关键学科 数据科学家使用上面所述的所有技术就可以把行业知识和数学知识转化为挖掘数据并提取为有用信息的(计算机科学方面的)应用。数据科学的核心是多个学科的交叉点(它还可能包含诸如机器学习和信息获取方面的知识)。
如今大量需要具有大数据分析经验的工程师和科学家。麦肯锡咨询有限公司预测:到2018年,满足数据科学家角色的人员将会出现短缺。数据科学的思想和实现 方法对许多其它学科也是很有用的。即使在你不愿意成为数据科学家的情况下,数据科学方面的技术仍然可以很好的补充你的工程技术。 数据科学应用在哪些地方
像云计算一样,数据科学正快速地获得关注、得到采用。根据谷歌搜索透视(以前的谷歌趋势)的统计结果,与这篇文章发表的前一年相比,数据科学方面的关注大 约已经翻倍。谷歌搜索透视本身就是数据科学实践的一个例子。图2展示了在2011年夏季到2012年春季期间互联网搜索方面的数据科学的使用频率得到迅猛 的增长:
图2.谷歌搜索透视上数据科学关注度方面的数据
数据科学快速地成为各种组织获取在线数据的主要技术手段(不管是爬取方式采集的还是根据像点击这样的用户行为网站内部采集)。像谷歌、亚马逊、脸谱和LinkedIn这些主要的互联网站点都有自己的数据科学团队处理他们自身的数据。 谷歌的页面排名算法的开发就是数据科学方面开发的早期的例子。谷歌爬取站点,然后给每个页面的伤的超链接指定一个数字权重,通过这个数字权重可以衡量这些 超级链接的相对重要性。(页面排名的所有详细信息只有谷歌自身清楚。)这个算法把页面内容的排名方式做为搜索方面的功能提供给大家。
像亚马逊和沃尔玛这样的大型在线零售商使用数据科学试图增加销售。它们根据用户搜索的商品和过去采购的商品向各个用户自动生成推荐列表。
LinkedIn是一个专业的社交网站,它维护着大量与个人相关的数据以及这些人的职业、兴趣和关系等数据。如此大量的社交数据就会产生多种推荐功能(比对对个人的、对一个组的和对一个公司的)和更深入的挖掘这些数据而生成LinedIn新产品的项目。 数据科学在互联网应用方面的一个令人眼睛一亮的例子是公司bitly。表面上看,bitly是一个让用户缩短任何URL为不超过19个字符的URL(这个 URL将永久存储在bitly的数据中心)的服务。对缩短后的URL的引用都会从bitly重新定向到原来的URL。然后bitly可以看到人们缩短了哪 个URL和其他用户点击的哪个URL。这种方法提供了大量的数据,这样bitly(和它的首席科学家希拉里.梅森)可以使用这些数据生成大量有关浏览习惯 方面的统计结果。注册到bitly的用户可以看到什么时候点击了他缩短的URL,是通过哪种推荐方式(电子邮件客户端、推特或者其他URL)进入的,以及 来自哪个国家的点击。商业公司还可以使用bitly追踪对某些网页内容访问的用户行为。 数据科学的开源工具
正如计算机编程不局限于一个语言或开发环境,数据科学也并不与一个工具或工具套件有关。在开源领域有一批丰富的工具可以促进数据科学的发展。它们包括大数据的数值计算工具,和用在复杂处理开发中的可视化和原型设计工具。表1列出了数据科学家可用的优秀开源工具和它们对应的角色: 表1. 用于数据科学的开源工具
工具 描述 Apache Hadoop 处理大数据的框架 Apache Mahout 应用于Hadoop的可扩展的机器学习算法 Spark 数据分析的集群计算框架 用于统计计算的R项目 易理解的数据操作和图形绘制 Python,Ruby,Perl 原型和产品的脚本语言 Scipy Python Python科学计算包 scikit-learn Python Python机器学习包 Axiis 交互式数据可视化工具
表1中列举的并不详尽,但代表了数据科学家工具箱内的一些核心元素。开源领域也充满了高度专业化和特定领域的库和工具(例如,用于交互式地图可视化和文字分析的实用工具)。 Hadooop,Mahout和Spark
互联网给了我们收集大量用户行为和习惯数据的机会。Apache
Hadoop是处理大数据的首选框架。对数据科学来讲,Hadoop是非常重要的,因为它是一个进行分布式数据处理的可扩展框架。并不是所有的数据科学问
题都需要进行大数据处理,不过当你的问题涉及到互联网级数据的时候,Hadoop就是理想的选择。实现谷歌页面排名算法的MapReduce框架就是数据
科学在大数据处理框架早期实现的例子。(Hadoop实现了MapReduce。)Apache
Pig可以让你更容易地访问Hadoop,而且它还引入了一种用来自动构建MapReduce应用的查询式语言。 Apache Mahout是Hadoop平台上可扩展性机器学习算法的具体实现。Mahout包括集群算法的可扩展性实现和(用于实现推荐系统的)批处理方式、多方协作的过滤算法的可扩展性实现。
另一个值得一提处理大数据的解决方案是Spark框架。Spark框架包含了一些优化措施,比如在内存内进行具有失效容忍机制的集群计算。 R项目
经常能在数据挖掘人员的工具箱里发现这样的工具:一种称作R的编程语言和开发环境。R关注的是统计计算和图形化。R的学习相对简单,而且在数据分析领域得到了广泛的应用。由于R是开发源代码的,而且是免费的,因此它是一种具有广泛用户基础的流行的语言。
R是一个多模式的语言,即它支持面向对象的编程、函数式编程,过程型编程以及命令行式编程风格。R语言是通过命令行接口来解释执行的,而且它还包括丰富的 生产级别的图形化功能。统计图形化是其首先创造的。 另外,通过使用其他软件包可实现动态的和交互式图形。图3展示了使用R语言生成的曲线图的例子:
图3.使用R语言实现的三维sinc曲线。 R编程语言是用C和Fortran语言开发的。R中的许多标准的内部函数都是用R语言自身编写的。R支持多种语言混合式编程,这样就能够让你从如C和Java TM语言来访问R对象。利用package功能,你就可以很容易地扩展R的功能。package可以使用R、C、Java和C编程语言编写。 |