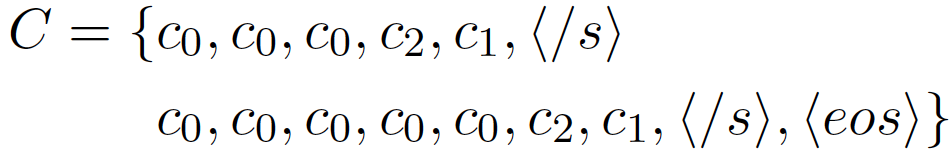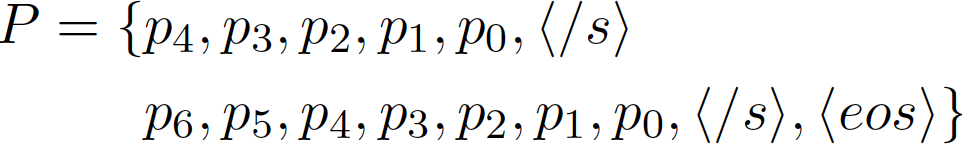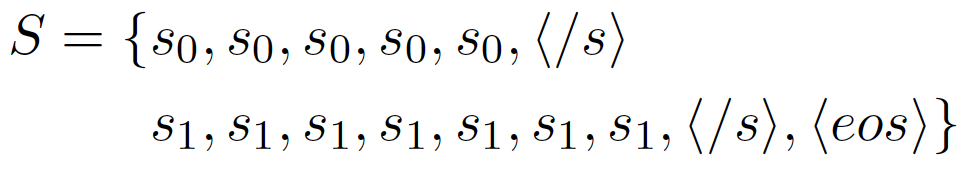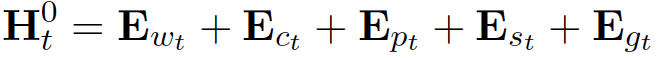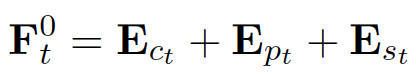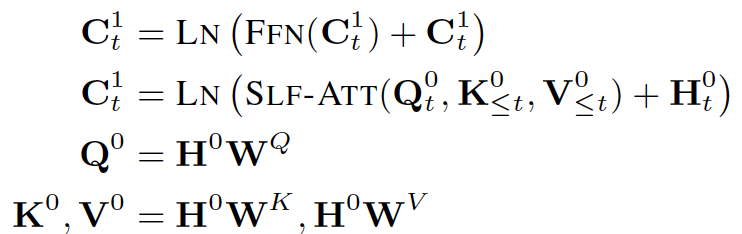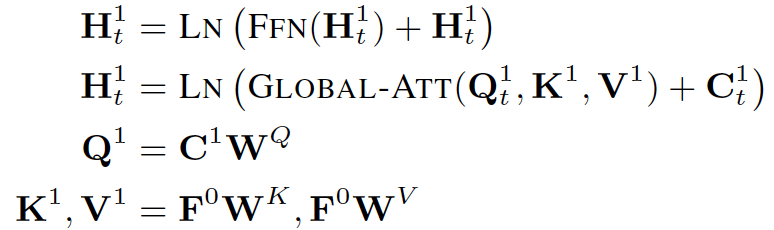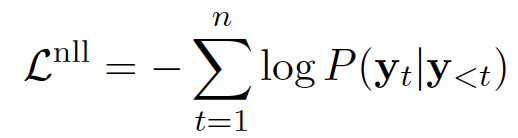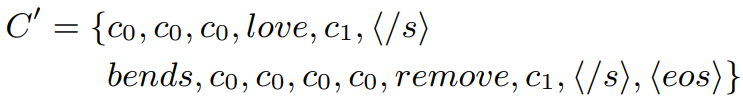SongNet模型是腾讯AI Lab NLP中心自研的一套基于预训练语言模型的硬格式控制下的文本生成模型。它能接受任意指定的格式进行文本生成,例如生成歌词、唐诗宋词、莎士比亚十四行诗等。以下为论文的详细解读。 Rigid Formats Controlled Text Generation 1 背景歌词、诗词等是比较独特的文体形式,有严格的格式、韵律等要求。平时我们见到的文本生成任务如对话生成、故事生成、摘要生成等多以自由生成方式为主,给定固定模板严格限制格式进行填词的文本生成任务研究较少。SongNet模型旨在解决此类硬格式控制的文本生成问题。例如,给定一首歌的歌词,让模型能够将歌词全部改写,或者只改写部分歌词。在改写的同时保证文本的格式正确、韵律合理、句子完整等基本的质量需求。具体的,给定《十年》这首歌词的格式,我们可以通过SongNet重新进行配词,并保证格式不变,可以根据原来的曲谱进行演唱: 原歌词:十年之前/我不认识你/你不属于我/我们还是一样/陪在一个陌生人左右/走过渐渐熟悉的街头 新配词:夜深人静/思念你模样/多少次孤单/想伴在你身旁/是什么让我如此幻想/为何会对你那般痴狂 2 方法2.1 问题定义 输入:一个模板 输出:将 2.2 模型框架
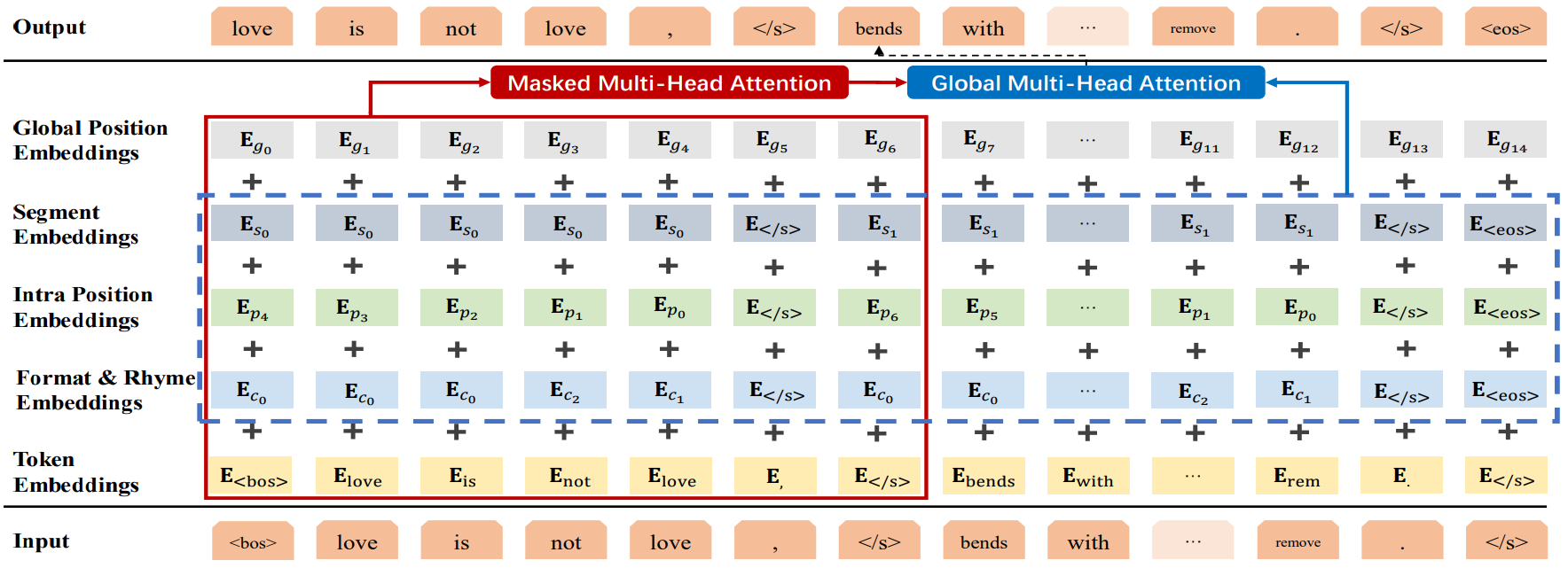
图1 模型框架 基于Transformer的自回归语言模型,我们提出了自己的框架。为了解决模板、韵律、句子完整性问题,我们定义了几种符号来对这些特殊的信息进行建模。 模板和韵律符号:
其中 内部位置符号:
模板中的每个句子都会有一个内部位置序列,特别强调的一点是,我们这里将符号倒序排列,旨在让模型能够学习到句子的一个渐进结束的过程,当遇到 句子符号:
对句子位置进行建模,每个符号代表句子在序列中的ID,旨在让模型推测出目前在生成的句子位置,捕捉学习到押韵的句对。例如莎士比亚的十四行诗押韵格式为“ABAB CDCD EFEF GG”,有了句子位置特征模型就会比较容易捕捉到1句和3句押韵,2和4押韵等。 训练的时候,所有的符号以及文本转化成向量后输入到基于Transformer的语言模型中:
为了让模型在auto-regressive的这个动态过程中能够看到模板的未来信息,我们还引入了另一个变量,只融合了之前定义的符号信息,没有输入的文本信息避免了右侧信息泄露:
然后通过两个Attention层对输入的信息进行建模,第一层是auto-regressive建模中的带masking的Attention建模机制:
第二层是能够看到模板全局信息的Attention层:
采用最大似然估计作为优化方法:
2.2 训练中的masking策略 在生成任务中,会遇到给定部分文本,补充其他文本的局部补全需求。例如,在模板中,给定部分句子,补全其他句子;在句子中,知道了部分词,补充其他词。为了使得模型有解决该类需求的能力,我们在预训练阶段,设计了masking策略: 模板中保留部分词,模型来学习预测其他的词。
这样模型就可以根据两侧的context信息进行预测生成,近似的有了双向语言模型的能力。 3 Inference方法我们采用了top-k sampling的解码方法来生成多样性好的结果,通过调节超参k可以平衡多样性和质量。 4 试验4.1 数据集 中文我们以宋词生成作为预测目标;英文生成莎士比亚十四行诗(sonnet)。 模型分预训练和微调两个阶段。在预训练阶段,中文语料主要是新闻和维基百科,英文语料是维基百科和BooksCorpus。 4.2 评测指标 除了常用的文本生成评测指标如ppl、distinct外,我们还专门设计了度量模板准确率(Format)、韵律准确率(Rhyme)和句子完整度(integrity)的指标。 4.3 结果
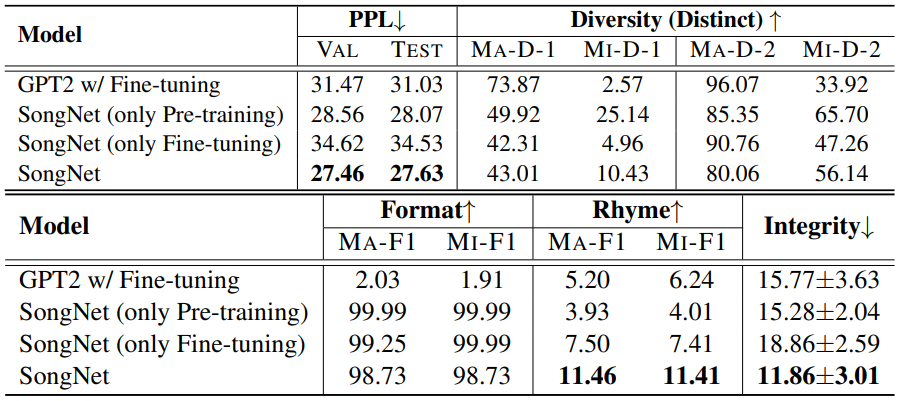
表1:宋词生成效果评测
表2:莎士比亚十四行诗效果评测 表1和表2分别是在宋词和十四行诗上的格式生成评测结果,可以看出我们的模型SongNet在ppl、多样性、模板准确率、押韵准确率、句子完整性上都取得了不错的指标。相比宋词,十四行诗的效果差一些,主要原因是十四行诗的训练样本太少(只有100首)。 5 例子1、指定模板生成
例子中模型不仅可以根据已有的格式模板(例如鹧鸪天、卜算子)进行生成,还能根据我们自己定义的格式进行宋词生成,而且押韵效果也不错。 2、预先填入词的生成
得益于masking的训练策略,我们的模型可以进行生成结果的精修,例如生成了一些结果之后,我们可以删掉不满意的部分,让模型重新进行局部补全生成,上面的结果可以看出,效果还是比较令人满意的。 3、歌词生成 正文开始我们提到可以通过SongNet进行歌曲配词,我们也试验了将《桥边姑娘》这首歌进行重新配词,模型可以轻松的产生成千上万首新的歌词,选择部分结果如下: 夜风扬/残月如霜/又见她在梳妆/一缕柔情凝结成冰凉/谁在空中遥想/她的影子浮现眼眶/孤独飘忽迷茫/怎不愿把这份思量/悄悄藏在心房/天涯两殇/你可曾相望/花落情殇/难道是梦乡/爱过恨过之往/秋水悠长/我却为你痴狂/岁月已成沧桑/寂寞守望/繁华盛放/只有对酒品尝/伴着忧伤流淌/夜风扬/好凄凉/醉看霓虹绽放/谁能看透这几度惆怅/苦涩与绝唱/都变得愈演愈勉强/痛彻愁肠帐/让时光停止流浪/当作路程远航/江山未央/回忆旧模样/地老天荒/何处话凄凉/值得我去吟唱/日出朝阳/映照整个过往/陪看红尘万丈/无力遗忘/寂寞依墙/等到白发苍苍/唯剩满眼悲 |