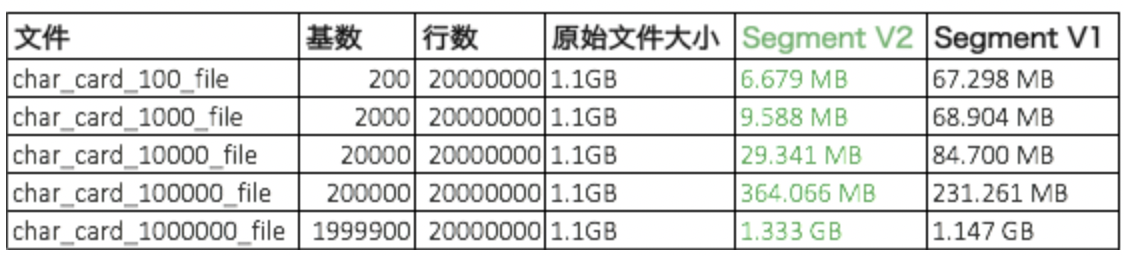
Apache Doris(Incubating) 0.12.0 已经发布了,这是 Doris 进入 Apache 孵化器后第四个正式版本。 此版本带来的新功能包括: 全新的存储格式SegmentV2此版本对底层的数据文件格式进行了完全重构。原有的存储格式是类似orcfile的列存格式,存在诸多的设计问题,如按字节流的读取方式效率低下、大量随机读问题、不支持字典压缩、不支持数据块的缓存、结构不清晰难以扩展等。 新的SegmentV2存储格式参考了Parquet的设计思路,引入了基于Page的最小数据存储单元,并将数据文件划分为数据区、索引区和元数据区三个部分。针对不同的列类型、索引格式实现了不同的Page编码方式,显著提升了数据的读写效率,并增强了数据格式的可扩展性。 在SegmentV2的基础上,0.12版本实现了如下重要功能: · 字典压缩编码原有的存储格式中,字符串类型都是采用Plain Text的格式进行存储的,这种朴素的方式在某些低基数字符串列的场景下,会极大地浪费存储空间。 SegmentV2通过Dictionary Page,实现了字典压缩编码,在不同基数的情况下可以节省数倍的存储空间。
· 基于Bitmap的二级索引之前版本的Doris只支持基于BloomFilter的二级索引,只能过滤block级别的数据,并且在某些低基数列上的效果欠佳。在0.12版本中,支持了基于Bitmap的倒排索引,可以在任意Key列上创建。通过倒排索引,可以更精准地进行数据查询和检索。测试中,通过倒排索引,可以提升数倍的查询性能。
· Page Cache和内存表Page是SegmentV2格式中,最小的数据单元,一个Page会被完整的解压并读取到内存中。Page一旦生成,是不可变更的,根据这个特性,此版本增加了Page Cache功能,通过在内存中缓存解压后的Page数据,可以避免大量的重复IO,降低磁盘IO。 同时基于Page Cache功能,也提供了一种内存表的实现方式。用户可以在建表时指定表的属性“in_memory”=“ true”,则系统会尽可能的保证该表的数据Page保留在Page Cache中,从而提升数据的访问效率。 · 延迟物化全新的存储格式提供了更清晰的数据读取逻辑,使得Doris能够支持延迟物化这种更高效的数据读取能力。延迟物化的含义,举例来说,当用户需要读取A、B、C三列的数据,并且在A列上有过滤条件时,系统会先读取A列并进行过滤,根据过滤后的行号再去读取B、C两列,这样可以显著减少B、C两列的读取数据量。根据测试,在某些场景下,延迟物化功能可以带来几十倍的性能提升。 Spark on Doris此版本实现了Spark Doris Connector,用户可以直接通过Spark对Doris中存储的数据进行查询。从Doris的角度看,将其数据引入Spark,可以使用Spark一系列丰富的生态产品,扩宽了Doris的想象力,也使得Doris和其他数据源的联合查询成为可能。 明细模型上的物化视图功能在之前的版本中,Doris仅支持在聚合模型(Aggregate Key)上创建上卷表(Rollup),而如果用户创建的是明细模型(Duplicate Key)表,则无法使用该功能。在新版本中,Doris支持了在明细模型上创建物化视图的功能。该功能使得用户可以更加灵活地进行数据建模。 当前该功能仅支持SUM、MIN、MAX三种上卷聚合方式,更多的聚合方式如HLL、BITMAP_UNION、AVG、COUNT等将在后续的3位版本迭代中陆续推出。
支持ORC格式数据的导入在0.11版本中支持了Parquet文件格式,而在0.12版本中,进一步支持了ORC格式的数据文件的导入,进一步降低了用户的使用门槛,可以更加方便地从不同数据源中导入数据。 动态分区在之前的版本中,数据表的分区(Partition)需要手动创建。对于一些例行任务场景,用户需要维护额外的脚本或服务来定期地增加新的分区或删除旧的分区。在新版本中,支持了动态分区的定义和创建,分区可以按照定义定期地进行创建和删除,用户无需再担心因分区未及时创建而导致数据无法导入的问题了。 差集、交集、Grouping Set0.12版本支持了更丰富的SQL语法和算子。其中差集(Expect)和交集(Intersect)算子避免了用户通过改写Join来获取想要的结果,同时也带来了查询性能的提升。 Grouping Set功能能够让用户更便捷地通过简单的SQL语法获取不同纬度的聚合查询结果,进一步降低了SQL的复杂度。 更多增强特性除了以上主要功能更新外,0.12版本也做了诸多性能和功能方面的改进。 · 插件框架和审计日志插件0.12版本分别实现了FE端和BE端的插件框架。该框架支持用户对一些功能组件进行定制化的开发和安装。目前该功能还处于实验阶段。系统提供了一个FE端的审计日志插件供使用,通过该插件,用户可以直接通过Doris的查询能力来分析Doris系统内的查询请求情况。 · 显著提升了Doris On Elasticsearch的性能通过更精细的谓词下推、以及API接口的改进,显著提升了Doris On ES性能。 · Bitmap聚合方式支持64位整型Bitmap聚合方式从支持32位整型扩展到了64位,使得可以在更多场景实现快速精确去重能力。 · 更多的列类型转换支持Float转Double,Date和Datetime的互转、Integer转Date/Datetime,以及Varchar转换为整型、浮点和日期类型等。通过更丰富的列类型转换,使得用户能够更灵活地应对业务场景的变更。 · 基于NIO模型的MySQL协议连接层通过XNIO框架(https://xnio.jboss.org/),Doris的连接层现在可以支持百万量级的连接请求。新的连接层框架可以在高并发场景降低Doris在连接协议上的开销和负载。 该功能可以通过添加FE的配置项:mysql_service_nio_enabled=true开启。 此外官方还透露,下一版本将支持更好的物化视图功能、Spark导入功能,并且对查询引擎性能做进一步地优化。 详情查看更新说明: https://mp.weixin.qq.com/s/oR6q-JsJEF3VNPGMAQfsHQ 下载地址: https://github.com/baidu-doris/incubator-doris/releases |