开发开源 Firefox 浏览器的非营利组织 Mozilla 宣布,其所推动地最大语音数据收集计划——Common Voice 平台已正式支持汉语普通话。在广大的 Mozilla 社群及语言专家伙伴的辛勤努力下,从现在开始,网友可到 Common Voice 的简体中文网站(https://voice.mozilla.org/zh-CN)录制音频。
● Mozilla 开始收集大陆地区汉语语音数据,更进一步充实其公开语音数据集
● 现已收集 27 种不同语言的语音文件,并将再扩大支持 72 种语言
● Common Voice 是史上最大的开源语音转录文字数据集,其最新发布的数据库包括来自超过 4.2 万贡献者的 18 种语言录制的语音文件,总长近 1,400 小时
语音接口是互联网未来的大势所趋。车载语音助理、智能手表、智能灯泡等等……内建语音识别技术的设备可谓与日俱增。然而,相关技术的创新仍面临着重大阻碍:有意打造语音辅助方案的创新公司、研究人员或各种开发者都需取得大量转录为文字的语音数据,才能训练机器学习的算法。但现有公开语音数据集的语音数据量与支持语种数都极其有限,而私有的语音数据不但仅掌握在少数几家公司手中,其费用还很高。
因此,Mozilla 自 2017 年 6 月起展开 Common Voice 计划,希望建立全球化的开源语音数据库,以应对语音接口的发展需求并突破现阶段的市场局限。Mozilla 认为,此类接口不该只把持在少数几家握有语音服务技术的厂商手中,而且,希望能让用户以自己的语言和熟悉的腔调来吸收和了解信息。
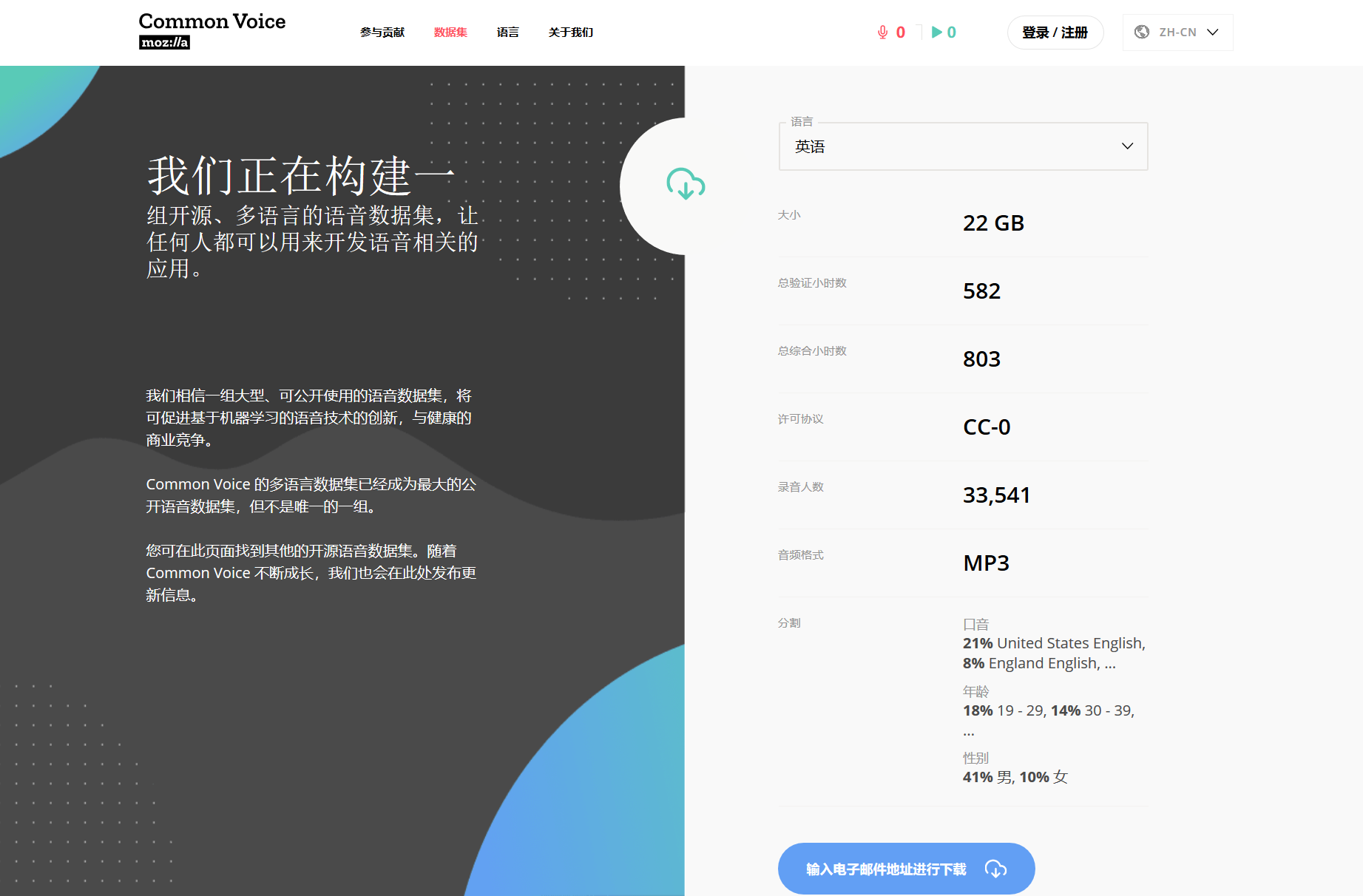
已收集包括汉语(普通话)在内的 27 种语音数据
Common Voice 在 2018 年 6 月开始收集多语言语音数据。从那时起,此项目便不断壮大,变得更全球化、更具包容性。在过去
10 个月间,大批的热血贡献者踊跃响应,已在 Common Voice 网站上发起 27 种语言的语音文件收集计划,另外还有高达 72
种语言的录音计划正在进行中。
最新加入的语言是汉语(普通话)。现在,世界各地的网友都可以到 https://voice.mozilla.org/zh-CN 网站“捐献声音”,或验证其他人的录音。
 语音贡献者可以选择保留项目记录,以掌握自己的录音记录。此外,还可以选择提供人口特征信息,以协助 Mozilla 改善用以训练语音识别引擎的语音数据。
如 Common Voice 收集的其他语言数据,Mozilla 对于汉语(普通话)的目标是要累积约 1 万小时的通过验证的音频,因为
1
万小时的音频量才足以训练出完备的语音识别系统,这样大家才能共同推动语音识别技术的进展。无论在上班途中、公交车上、午休时间、家里,还是与亲朋好友齐聚一堂时,都可以通过
voice.mozilla.org 网站或 iOS 应用,只要有手机或计算机,你就能捐出声音或验证其他人的音频。
Mozilla 开源创新计划总监 George Roter 表示:「就算一个人只录或听几秒钟的音频,但如果贡献者多达数十万,加起来的数据量就会非常惊人!当更多人都愿意出一份力时,这套语音数据集的价值就能更快提升。」
发布多语言语音数据集
Mozilla
将不忘初衷,继续充实语音数据集的内涵,使其成为人人可用的公共资源。并已于今年二月发布第一批的多语言语音数据集,其中共涵盖 18
种语言的录音文件,包括:英语、法语、德语和汉语(台湾地区)等广泛通行的语言,以及威尔士语及卡比尔语等较为冷门的语言。Common Voice
至今已收集超过 4.2 万人贡献的录音,总长度约 1,400 小时,且语音数据量仍在持续增长中。
在此数据集发布后,Common Voice 的规模已超越其他同类型的语音数据集,并已将数万人的录音文件及对应文字开放给公众使用(采 CC0 授权)。任何人都可到 Common Voice 网站下载完整的语音数据集。
 George Roter 进一步表示:「Mozilla
致力于促进更加多元化的创新语音科技生态系的发展。我们不但希望能自行推出语音技术的产品,也立志倾力支持研究人员及小型企业的发展,在建立全球最大公共的多语言语音数据集的过程中,我们很荣幸得到越来越多人的帮助,也很感谢志愿者们的热情相挺,让我们成功开展对于汉语普通话的支持。」
稿源:cnBeta |






