北京大学近日开源了一个全新的中文分词工具包 pkuseg ,相比于现有的同类开源工具,pkuseg 大幅提高了分词的准确率。 pkuseg 由北大语言计算与机器学习研究组研制推出,具备如下特性:
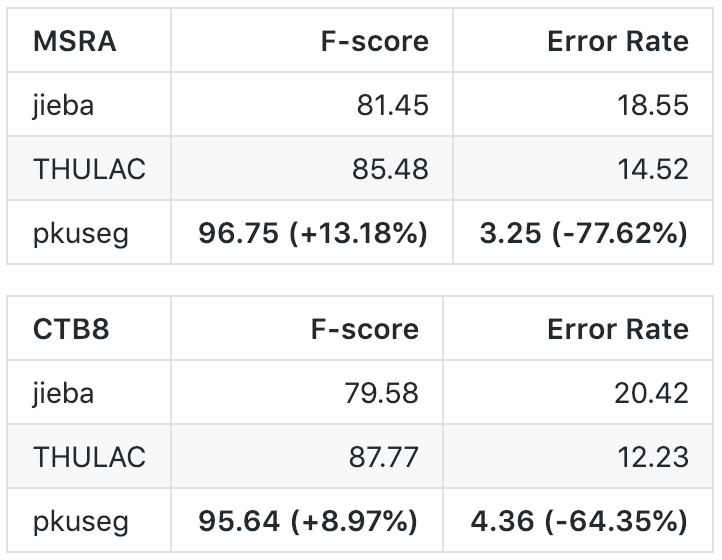
性能对比 在 Linux 环境下,各工具在新闻数据 (MSRA) 和混合型文本 (CTB8) 数据上的准确率测试情况如下:
预训练模型 分词模式下,用户需要加载预训练好的模型。我们提供了三种在不同类型数据上训练得到的模型,根据具体需要,用户可以选择不同的预训练模型。以下是对预训练模型的说明: MSRA : 在 MSRA(新闻语料)上训练的模型。新版本代码采用的是此模型。下载地址 CTB8 : 在 CTB8(新闻文本及网络文本的混合型语料)上训练的模型。下载地址 WEIBO : 在微博(网络文本语料)上训练的模型。下载地址 更多详情可查阅项目仓库。 |