由于近年来虚拟个人助理的迅猛发展和深度学习算法的运用所带来的字词识别准确率的飞跃,自动语音识别 (ASR) 已经得到广泛的采用。许多语音识别团队都依靠 Kaldi,这是一款广受欢迎的开放源代码语音识别工具包。据 Google 博客消息,Kaldi 现在提供 TensorFlow 集成。 通过此集成,使用
Kaldi 的语音识别研究人员和开发者将能够在他们的 Kaldi 语音识别管道中,使用 TensorFlow
来探索和部署深度学习模型。这样,Kaldi 社区可以构建更出色、更强大的 ASR 系统,并为 TensorFlow 用户提供一种利用庞大的
Kaldi 开发者社区的经验探索 ASR 的途径。
构建一套能够理解每种对话语言、口音、环境和类型的人类语音的 ASR
系统是一项极其复杂的任务。传统的 ASR
系统可被视为由许多独立模块组成的处理管道,其中,每个模块的运行都基于上一个模块的输出。原始音频数据从管道的一端进入管道,然后从另一端输出已识别语音的转录文字。在
Kaldi 中,会以各种方式对这些 ASR 转录文字进行后处理,以便支持不断增多的最终用户应用。 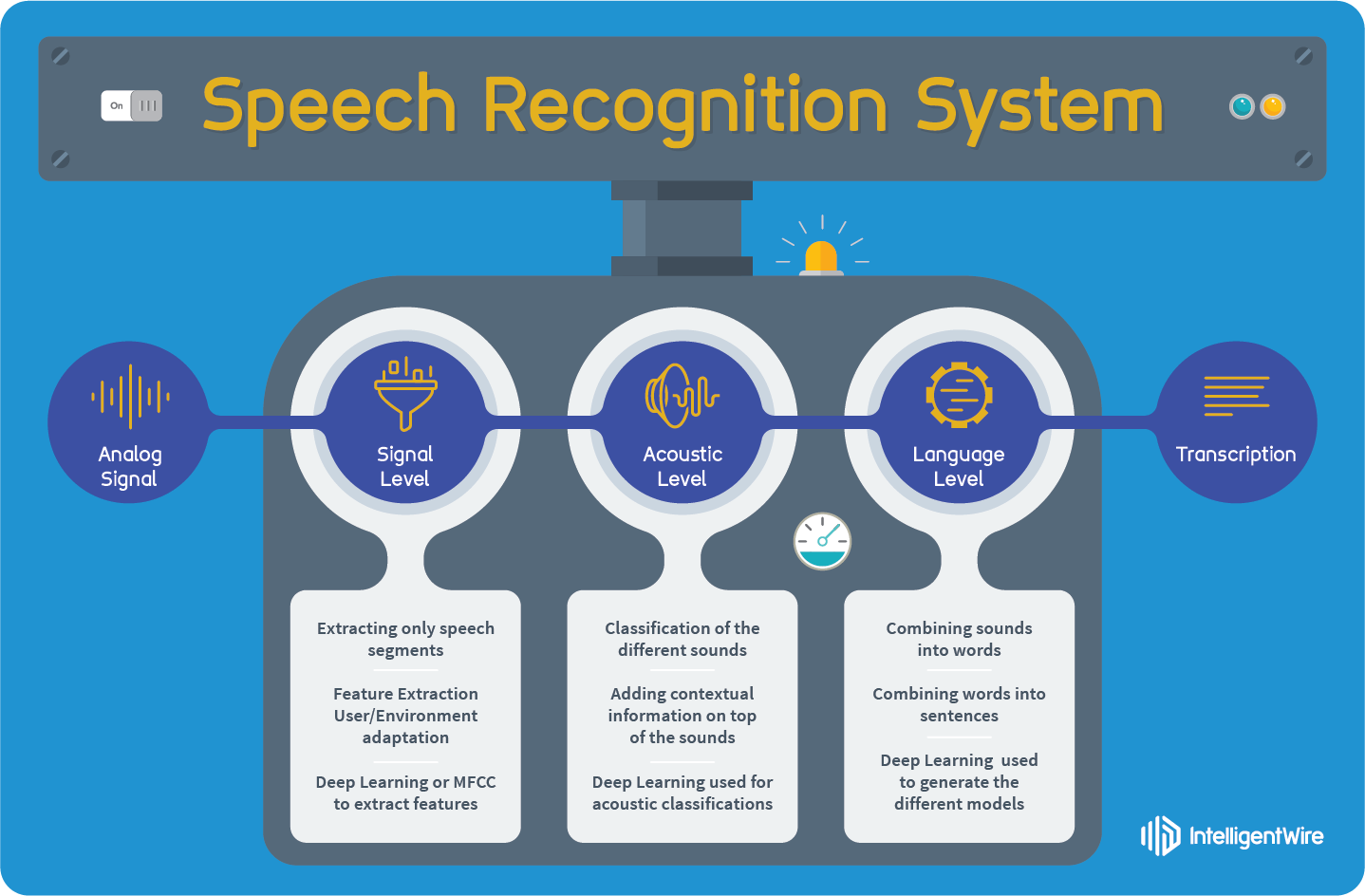
在过去几年里,人们一直使用深度神经网络代替许多原有的
ASR 模块,最终使得字词识别准确率得到显著的提升。这些深度学习模块通常需要处理海量的数据,而 TensorFlow
则可以简化这一处理工作。然而,在开发生产级的 ASR 系统时,仍有几个重大的挑战需要克服: 算法 - 深度学习算法在针对手头的任务进行定制时效果最佳,包括声音环境(如噪音)、所讲的特定语言、词汇范围等。这些算法一经部署,再要修改就不是很容易了。 数据 - 针对不同的语言和不同的声音环境构建 ASR 系统需要多种类型的大量数据。如此庞大的数据并非总能得到,也可能并不适合用例。 扩展 - 能够支持庞大使用量和许多语言的 ASR 系统通常要消耗大量的运算资源。
能够说明这些挑战的
ASR 系统模块之一是语言模型。语言模型是最先进的 ASR
系统的关键部件之一,它们提供语言上下文,帮助预测词语的正确顺序并区分发音相似的词语。借助最新的机器学习突破,语音识别开发者现在利用基于深度学习的语言模型,也称为神经语言模型。特别是,相对于传统的统计方法,循环神经语言模型的识别结果更胜一筹。
然而,神经语言模型的训练和部署相当复杂,而且颇为耗时。将
TensorFlow 集成到 Kaldi 中已经将 ASR 开发周期缩短了一个数量级。如果某个语言模型在 TensorFlow
中已存在,则从模型到概念证明只需要几天时间,而不是几周时间;对于新模型,开发时间可从几个月缩短到几周。在 Kaldi 生产管道中部署新的
TensorFlow 模型还很简单,这对每个直接使用 Kaldi 以及未来很可能造福于每个人的更智能的 ASR 系统的人来说,不啻为一大福音。
类似地,这种集成让
TensorFlow 开发者能够轻松访问强大的 ASR 平台,能够将现有的语音处理管道(例如 Kaldi
强大的声学模型)集成到他们的机器学习应用中。Kaldi 模块可以为 TensorFlow
深度学习模块训练提供输入,模块的更换干脆利落,为探索研究提供了许多便利,同时还可重复利用生产中使用的管道来评估模型的质量。
稿源:谷歌开发者博客 | 





