变量
函数
用户定义的结构体
如果你有兴趣,可以看看 Pinecone 的引导页(landing page)或者它的 GitHub repo。
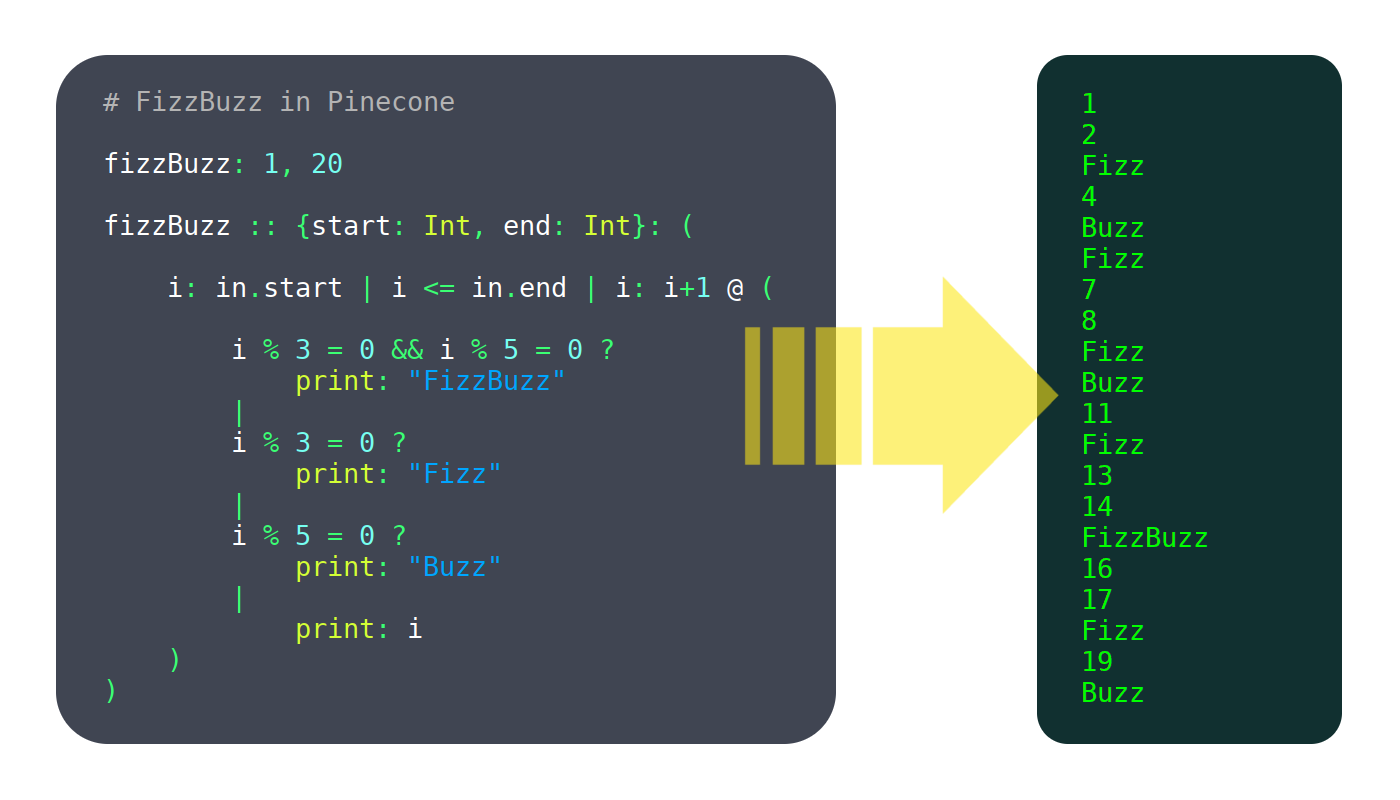
我不是一个专家。当我开始这个工程的时候,我对我所做的事情还没有方向,但我还是没有放弃。我在语言创建上的级别为0,只是读了一点点在线的资料,也没有遵循我给出的那些建议。
不过,我还是制造了一个完整的新语言。并且它能工作。所以我一定做了正确的事情。
在这篇文章中,我将深入展示管线 Pinecone (以及其他编程语言)把源码变成魔法。
我也会谈谈我已经做出的一些权衡,以及为什么我会做出那些决定。
这绝对不是制作编程语言的完整教程,但是如果你对语言开发感到好奇,那么这是一个好的开始。
入门
“我都不知道我该从哪里开始”,当我告诉其他开发人员我在写一门语言时,我通常会得到这样的回应。如果听后的反应也是这样,我现在将通过一些已经尝试过的决定和步骤,来告诉你如何开始一门新语言。
编译型 vs 解释型
语言主要有两种类型:编译型和解释型:
编译器会计算出一个程序将执行的操作,将其转换为“机器代码”(计算机可以运行的格式,非常快),然后保存以便稍后执行。
一个解释器逐行逐步执行源代码,弄清楚它在做什么。
技术上,任何语言都可以被编译或解释,但是一种或另一种语言通常对于特定语言更有意义。一般来说,解释往往更加灵活,而编译往往具有更高的性能。但这只是解决复杂问题前的预热。
我高度重视性能,我看到缺乏高性能和简单性的编程语言,所以我去编译了 Pinecone。
这是需要今早确定的重要决定,因为很多语言设计决策受到它影响(例如,静态类型对于编译型语言来说是一个很大的好处,但对于解释型语言而言并不是那么重要)。
尽管 Pinecone 是按照编译型设计,但它也有唯一一个可运行的,功能完整的解释器。原因我稍后会解释。选择一门语言
我知道这有点像是一个元数据,但编程语言本身就是一个程序,因此你需要用一种语言编写它。 我选择了 C++ ,因为它的性能和庞大的功能集。此外,我其实很喜欢使用 C ++ 工作。
如果你正在编写一种解释性语言,那么在编译语言(如 C、C ++ 或 Swift )中编写将是非常有意义的,因为你的解释型语言中的性能损失及其对应的解释器将会更加复杂。
如果你打算编译,较慢的语言(如 Python 或 JavaScript )是更为可接受的。编译时间可能很糟糕,但在我看来,运行时间差别不大。
高级设计
一门编程语言通常被构造为一类管线。也就是说,它通常拥有几个阶段。每个阶段的数据都会以明确的方式被格式化。还具有将数据从这一阶段转换到下一个阶段的功能。
第一个阶段是一串包含了整个输入源文件的字符串。最终阶段是可以被运行的东西。我们逐步完成 Pinecone 管线的时候,这一切就会变得清晰起来。
Lexing 词法

大多数编程语言的第一步是词法分析或分词。 “Lex” 是词法分析的缩写,这是一个非常棒的词,是将一大堆文本分解成多个符号。 “tokenizer” 这个词更有意义,但是,“词法分析”说起来很有趣,因此我经常使用它。
标记
标记或记号是语言的一个单元。标记可能是一个变量或函数名(也叫标识符),也可能是一个操作符或数字。
词法分析器的任务
词法分析器将包含源码的文件作为输入字符串,输出包含标记符号的列表。
流水线(就是编译过程)后面的阶段将不再参考这些字符串源代码,所以词法分析器必须产生所有后面各阶段需要的信息。之所以会有这样相对严格的格式设计,是因为这个阶段词法分析器可以做一些工作,比如移除注释或检测标识符或数字等。如果你将这些逻辑规则放在词法分析器里,那么在构造语言的其它部分时就不必再考虑这些规则了,而且你可以方便地在同一个地方集中修改这些语法规则。
Flex
我开始开发这个语言,第一件事情就是写了一个简单的词法。不久之后,我开始学习可以让词法更简单正确的工具。
这个小工具就是 Flex ,一个生成词法的程序。你传入一个具有特定格式来描述语言语法的文件。它会生成一个 C 语言语法的程序代码。
我的决定
我选择暂时保留最初写的词法分类器。因为到最后我没有看到 Flex 的明显优势,至少不能达到添加依赖和完成复杂构建。
我的词法分类器只有几百行代码,几乎没有什么问题。迭代我的词法分类器也给了更多的灵活性。例如在不编辑多个文件的情况下向语言添加操作符。
语法分析

管线流程的第二阶段就是语法分析器。语法分析器把标识符列表解析为一个带结点的树。用于存储这种数据的树称为抽象语法树,即 AST 。 最后在 Pinecone 的抽象语法树中不会包含任何标识符类型信息,它就是一个简单的结构化的标识符。
解析器的作用
解析器将结构添加到词法分析器产生有序列表中的令牌。 为了阻止歧义,解析器必须考虑括号和操作顺序。 简单的解析运算符并不怎么困难,但随着更多的语言结构的添加,解析变得非常复杂。
Bison
再次,有一个决定涉及第三方库。 主要的解析库是 Bison。 Bison 的作品很像 Flex。 你使用存储语法信息的自定义格式编写文件,然后 Bison 使用该文件生成将执行解析的 C 程序。 但我没有选择使用 Bison。为什么自定义更好
在词法分析器中,使用我自己的代码这是相当明显的决定。词法分析器是一个这样一个小程序,我自己不写,感觉就像不会写我自己的“left-pad”一样愚蠢。
解析器是另一回事。我的Pinecone解析器目前是750线长,我写了三个,因为前两个都是垃圾。
我做出这样的决定原因有很多,虽然不算顺利,但大部分都是正确的。主要内容如下:
最小化工作流中的上下文切换:C ++和Pinecone之间的上下文切换是不够的,而不会抛出Bison的语法
保持构建简单:每次语法改变Bison必须在构建之前运行。这可以是自动化的,但是在构建系统之间切换时会变得很痛苦。
我喜欢构建很酷玩意:我没有做Pinecone,因为我认为这很容易,所以为什么我自己决定一个中心角色?自定义解析器可能不是微不足道的,但它是完全可行的。
一开始我并不完全确定这是否可行,但是我对Walter Bright(C ++的早期版本的开发人员,D语言的创造者)不得不说的是:
有一点更有争议的是,我不会因为词法分析器或解析器生成器和其他所谓的”编译器的编译器“浪费时间,这些太浪费时间。编写词法分析器和解析器是编写编译器的一小部分工作。使用一个生成器将花费与编写一个手工一样多的时间,它将把您与生成器(在将编译器移植到一个新平台上非常重要)相结合。生成器也有时候会发出糟糕的错误信息和不幸的声音。行为树(Action Tree)
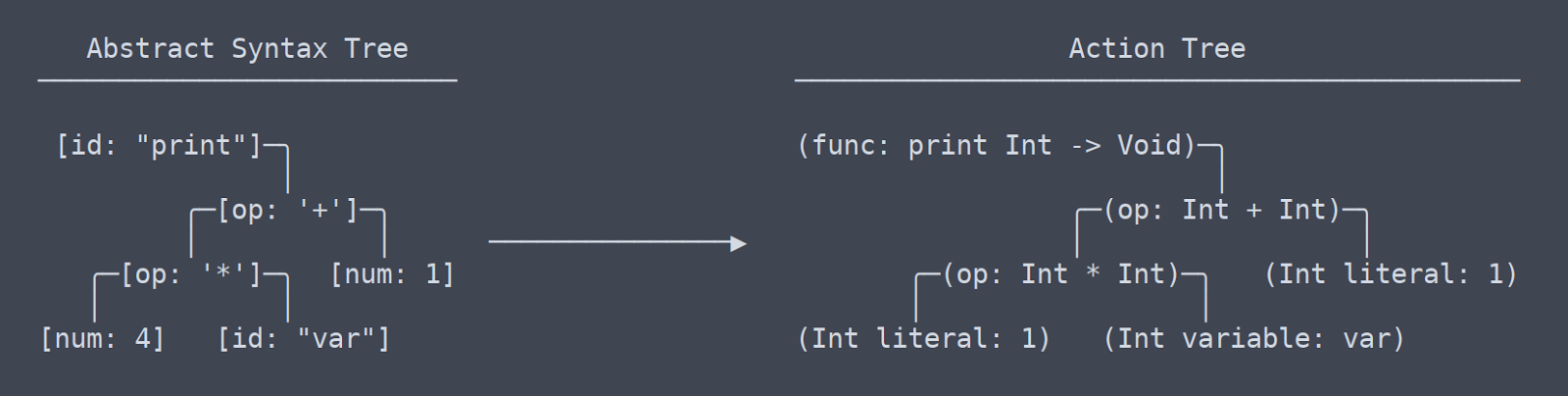
我们现在已经离开了有共同术语或者通用术语的领域,至少这些术语我不认识。从我的理解,我所谓的‘行动树' 是最类似于 LLVM 的 IR(中间表示)。
我花了相当长的一段时间弄清楚,行为树和抽象语法树之间有一个细微但非常重要的区别,我们应该区别对待(这促成了解析器的改写)。行为树 vs AST
简单来说,行为树是带有上下文的 AST。上下文是一个函数返回的类型的信息,或者两个地方使用的变量实际上是相同的变量。 因为它需要弄清楚并记住所有这些上下文,生成行为树的代码需要大量的命名空间查找表和其他的东西。
运行行为树
一旦我们有了行为树,运行代码就很容易了。 每个行为节点都有一个函数“execute”,它接受一些输入,不管行为应该如何(包括可能调用子行为),返回行为的输出。 这是行为中的解释器。
编译的选择
等等,Pinocone 不是应该先编译吗?是的,但是编译起来要比解释复杂的多,有几种解决方案:
新开发一个编译器
听起来是个好办法,我喜欢创造东西,早就想好好研究下编译领域了。
但是,写一个编译器并不是将语言的每个元素翻译成机器代码这么简单,因为有很多不同的架构和操作系统,个人想要编写一个跨平台的编译器不切实际。
即使是 Swift 团队的 Rust 和 Clang 也不想从头开始编写,他们的办法是...
LLVM
LLVM 是一个编译工具集,基本上就是一个库,可以把你的编程语言编译成可执行文件,看似是完美的选择,所以我马上使用了它,但不幸的是当时并未意识到水有多深。
LLVM 即使没有汇编语言那么难,也是一个异常庞大的库,几乎没法使用。即使他们有很好的帮助文档,但是我觉得在完全使用 LLVM 实现 Pinecone 之前,我还要多积累些经验。
转译
我想快速编译 Pinecone,所以我转向了一种可行的方法:转译。
我写了一个 Pinecone 到 C ++ 转译器,并添加了使用 GCC 自动编译输出源码的功能。 这个目前适用于几乎所有 Pinecone 程序(但也有例外)。 它不是一个特别便携或可扩展的解决方案,但是个可用的临时解决方案。
未来
假设我继续开发 Pinecone,它迟早将得到 LLVM 的编译支持。 怀疑无论我做了多少工作,转译器永远不会完全稳定工作,LLVM 的好处则很多。 问题是什么时候我才能有时间在 LLVM 中做一些示例项目,并掌握它。
在此之前,解释器对于微不足道的程序是非常好的,并且 C ++ 转译适用于大多数需要更多性能的时候。
结论
我希望我所编写的编程语言对你来说简单明了。如果你想自己做一个,我强烈推荐它。还有很多实现细节需要弄清楚,这里的大纲应该对你有所帮助。
这是我给出的入门建议(记住,我真的不知道我做的什么,所以仅举个例子):
如有疑问,请选择解释型的。解释型语言通常更易于设计、构建和学习。如果你确定你想要做的是编译型语言,我不会阻止你尝试编写一个,但持观望态度。
当谈到词法分析器和解析器,选择任何你想要的。这里有很多自己编写和反方的有效论据。最后,如果你给出了你的设计,并以合理的方式实现了一切,这并不重要。
从本文结束部分中的管道中学到一些技巧。我在设计管道时有很多尝试和错误。我试图消除AST,将AST变成action树,以及其他糟糕的想法。这个管道可以工作了,所以不需要改动它,除非你有一个很好的主意。
如果你没有时间或动机来实施复杂的通用语言,请尝试像Brainfuck一样实现一个深奥的语言。这些解释器可以短至几百行。
很抱歉我在Pinecone的实现过程中做了一些糟糕的决定,但是我已经重写了大部分受这种错误影响的代码。
现在,Pinecone已经足够好了,特别是它的功能,可以接受改进。编写Pinecone对我而言是一项非常受益和愉快的经历,它才刚刚开始。





