很多公司和科技博客都在鼓吹“人工智能”代表着未来,以及如何运用“机器学习”来改进技术并超越竞争对手。 但机器学习究竟要怎么用呢?它是否只是2017年的一股潮流而已? 简短的说:在大多数情况下它确实只是个流行语,但同时它是有用的,它也可以是革命性的。 机器学习是什么? 以它最原始的形式来说,机器学习是实践近似函数的艺术,或者说是做出有根据的推测。它与专业人士有相似的概念,比如一名资深管道工会拥有根据查看到的房屋中漏水情况,快速准确地判断造成漏水原因的经验。在机器学习中,我们把这种经验称为“大数据”。水管工看到和解决的每一个问题,都会获得一个新的“数据点”,并可以利用这些知识来解决将来遇到的类似问题。
所有的这一切看起来似乎都很美好,但对于近期机器学习热度的跃升,我敢于称其为流行语也是有原因的。机器学习几乎从来不是最终答案。它很容易使可以更容易解决的问题复杂化 - 比如根据没有理由重新设计 for-loop !目前大多数采用“机器学习”的公司实际上并没有真正使用机器学习的技术,或者只是把正常的算法开发挂名机器学习以达到营销目的,亦或者是在生产过于复杂、计算量密集、昂贵的和根本不必要的问题解决方案,来解决一些本来可以使用常规手段解决的问题。 事实上,当正确应用于有效的问题时,它可能是一个难以置信的工具。但是什么是有效的问题?虽然并不是最终确定机器学习问题的最终目的,但这里是一个方便的清单,用于确定问题是否值得采用机器学习方法,或者是更适合留给标准的分析解决方案。 适合机器学习的问题应具备:
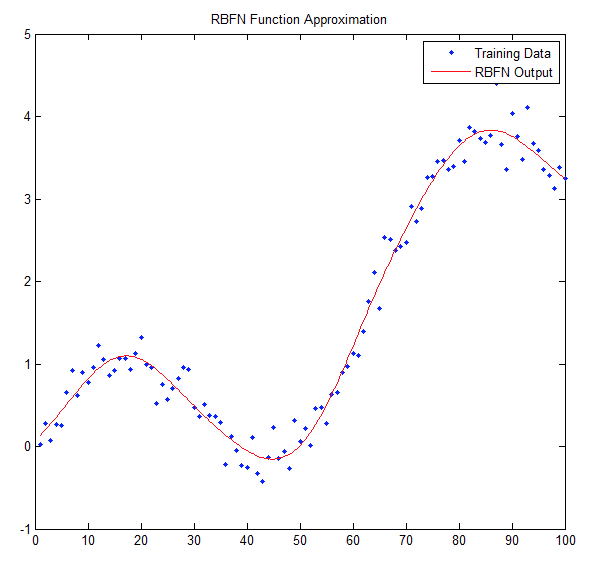
一些适合此清单的机器学习问题的流行示例包括:医学图像处理、产品推荐、语音理解、文本分析、面部识别、搜索引擎、自动驾驶汽车、增强现实和预测人类行为。 机器学习面临的最大挑战之一是处理系统中的不确定性(即同一输入不能保证一致的输出)。我们会通过这篇文章的其余部分来解释,例子是试图预测多伦多的天气,前提是我们有多伦多天气的历史数百年的大数据。 这个问题很复杂 - 准确的预测需要有天气科学方面的培训和经验的专家。这个问题是具备不确定性的 - 因为2016年2月23日的天气很冷,并不意味着2017年2月23日的天气是一样的,尽管它们有相同的历史数据。这个问题还是多维度的 - 风力模式、雨水模式和影响天气的各个因素都可以作为问题的一个新的维度。我们必须尽量使用我们所拥有的信息来预测系统的输出(预测天气) - 我们要做出最合理的猜测。 对于机器学习来说,我们最合理的猜测或近似函数几乎总是关于数学的创造性使用 - 不管是统计量/概率、向量、优化或其他数学方法。有几种核心类型的机器学习问题,可以帮助确定哪种解决方案最适合问题:分类、回归和聚类。在我们的例子中,我们正在研究的是一个回归问题 - 试图预测数据的持续趋势。有几种训练系统的核心方法,或提供系统学习经验的核心方法:有监督学习、无监督学习和强化学习。在我们的例子中,我们展示的是有监督学习,所有的训练数据的输入和输出都是已知的。我们给它输入多伦多的历史日期,然后知道当天的天气是什么(输出)。定义问题和训练模型可以让确定用于训练机器学习算法的方法变得简单。 至此,你已经决定要预测天气(或者解决一个不同的机器学习问题),而且你已经使用上面的清单确定这是一个真实有意义的问题。那要从哪里入手?下面是一个关于解决机器学习问题步骤的简要指南:
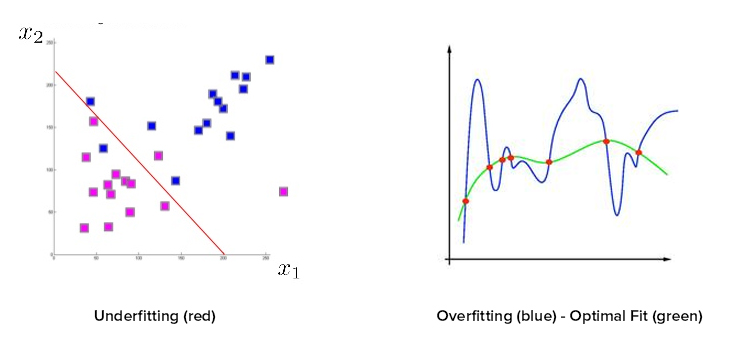
接下来用天气预测的问题来实践上面的步骤: 第一步是定义有意义的数据。什么属性是有意义的,怎样去定义一个“好”的数据点和“坏”的数据点?可以拿几个例子中的属性来解释一下,比如说温度、降雨量和风速这三个属性,就可以基本了解指定某天的天气。如果我们同时有多伦多人年龄中位数这样的属性,就应该把这样的属性排除在有效数据之外,因为它与问题无关,可能会使结果变得混乱。 第二步,我们已经通过调查确定问题是一个应该使用有监督学习的方法的回归问题。 第三步需要选择一种实际的机器学习方法,在这就不讨论太多细节,简单来说就是选择线性回归。 第四步是获取训练数据(并留下30%的数据做测试之用)。 第五步就是实际的训练和测试。 从这些步骤你可能已经注意到,实际训练算法是在最后的也是最不关键的异步。创建强大的机器学习的关键是提前确保你拥有有意义的数据,和定义清晰、明确的问题和解决方案。 即使你有了正确分类、定义明确的解决方案,也有了有意义的数据,合适的测试数据,并将异常值纳入数据趋势,仍然有很多地方可能出错。最常见的,许多机器解决方案背后的致命错误,往往是低度拟合/过度拟合(under/overfitting)。拟合,或者说高偏差,意味着最终的近似函数太过简单,不能很好的代表数据的趋势。试想如果我们试图在多伦多的一年温度中画出一条直线,你会发现这条直线很难撞到任何一个数据点。在低度拟合和过度拟合两者中,更常见也更危险的是过度拟合,或者也叫过高方差。在这种情况下,近似函数是很复杂的,也不能代表数据趋势。过度拟合通常会产生比低度拟合更差的结果,并且大家很容易陷入这样的陷阱。
这篇文章仅仅是机器学习的基本介绍,现在有越来越多的学习资源,在很多语言和 GUIs 中(目前最好的机器学习资料大多适用 Python),已经有了许多机器学习现成的算法和测试数据集,包括 Theano、Tensorflow、Weka 甚至可以在 Octave 和 MatLab 中使用。 资源地址:
<本文由开源中国编译自:symbilitysolutions> |