前言
之前有看到用很幽默的方式讲解Windows的socket IO模型,借用这个故事,讲解下linux的socket IO模型;
老陈有一个在外地工作的女儿,不能经常回来,老陈和她通过信件联系。
他们的信会被邮递员投递到他们小区门口的收发室里。这和Socket模型非常类似。
下面就以老陈接收信件为例讲解linux的 Socket I/O模型。
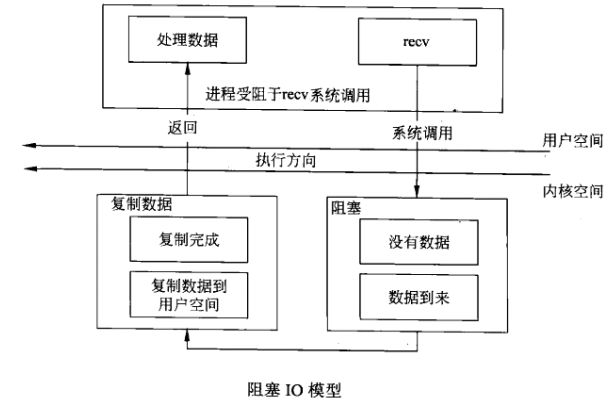
一、同步阻塞模型
老陈的女儿第一次去外地工作,送走她之后,老陈非常的挂心她安全到达没有;
于是老陈什么也不干,一直在小区门口收发室里等着她女儿的报平安的信到;
这就是linux的同步阻塞模式;
在这个模式中,用户空间的应用程序执行一个系统调用,并阻塞,
直到系统调用完成为止(数据传输完成或发生错误)。
Socket设置为阻塞模式,当socket不能立即完成I/O操作时,进程或线程进入等待状态,直到操作完成。
如图1所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
|
/*
* \brief
* tcp client
*/
#include
#include
#include
#include
#include
#define SERVPORT 8080
#define MAXDATASIZE 100
int main(int argc, char *argv[])
{
int sockfd, recvbytes;
char rcv_buf[MAXDATASIZE]; /*./client 127.0.0.1 hello */
char snd_buf[MAXDATASIZE];
struct hostent *host; /* struct hostent
* {
* char *h_name; // general hostname
* char **h_aliases; // hostname's alias
* int h_addrtype; // AF_INET
* int h_length;
* char **h_addr_list;
* };
*/
struct sockaddr_in server_addr;
if (argc < 3)
{
printf("Usage:%s [ip address] [any string]\n", argv[0]);
return 1;
}
*snd_buf = '\0';
strcat(snd_buf, argv[2]);
if ((sockfd = socket(AF_INET, SOCK_STREAM, 0)) == -1)
{
perror("socket:");
exit(1);
}
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(SERVPORT);
inet_pton(AF_INET, argv[1], &server_addr.sin_addr);
memset(&(server_addr.sin_zero), 0, 8);
/* create the connection by socket
* means that connect "sockfd" to "server_addr"
* 同步阻塞模式
*/
if (connect(sockfd, (struct sockaddr *)&server_addr, sizeof(struct sockaddr)) == -1)
{
perror("connect");
exit(1);
}
/* 同步阻塞模式 */
if (send(sockfd, snd_buf, sizeof(snd_buf), 0) == -1)
{
perror("send:");
exit(1);
}
printf("send:%s\n", snd_buf);
/* 同步阻塞模式 */
if ((recvbytes = recv(sockfd, rcv_buf, MAXDATASIZE, 0)) == -1)
{
perror("recv:");
exit(1);
}
rcv_buf[recvbytes] = '\0';
printf("recv:%s\n", rcv_buf);
close(sockfd);
return 0;
}
|
显然,代码中的connect, send, recv都是同步阻塞工作模式,
在结果没有返回时,程序什么也不做。
这种模型非常经典,也被广泛使用。
优势在于非常简单,等待的过程中占用的系统资源微乎其微,程序调用返回时,必定可以拿到数据;
但简单也带来一些缺点,程序在数据到来并准备好以前,不能进行其他操作,
需要有一个线程专门用于等待,这种代价对于需要处理大量连接的服务器而言,是很难接受的。
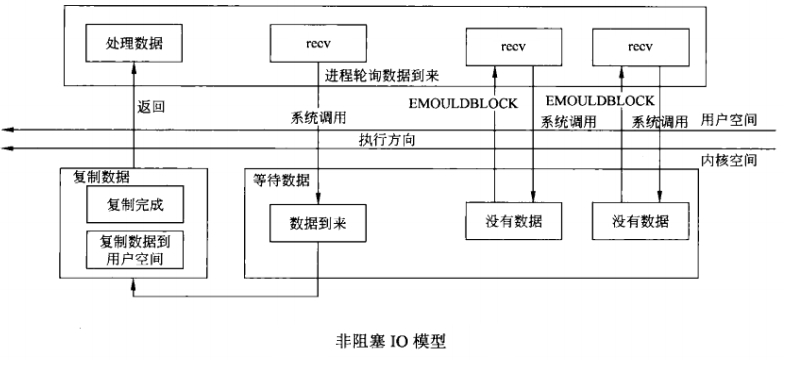
二、同步非阻塞模型
收到平安信后,老陈稍稍放心了,就不再一直在收发室前等信;
而是每隔一段时间就去收发室检查信箱;
这样,老陈也能在间隔时间内休息一会,或喝杯荼,看会电视,做点别的事情;
这就是同步非阻塞模型;
同步阻塞 I/O 的一种效率稍低的变种是同步非阻塞 I/O。
在这种模型中,系统调用是以非阻塞的形式打开的。
这意味着 I/O 操作不会立即完成, 操作可能会返回一个错误代码,
说明这个命令不能立即满足(EAGAIN 或 EWOULDBLOCK),
非阻塞的实现是 I/O 命令可能并不会立即满足,需要应用程序调用许多次来等待操作完成。
这可能效率不高,
因为在很多情况下,当内核执行这个命令时,应用程序必须要进行忙碌等待,直到数据可用为止,或者试图执行其他工作。
因为数据在内核中变为可用到用户调用 read 返回数据之间存在一定的间隔,这会导致整体数据吞吐量的降低。
如图2所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
|
/*
* \brief
* tcp client
*/
#include
#include
#include
#include
#include
#include
#include
#include
#include
#define SERVPORT 8080
#define MAXDATASIZE 100
int main(int argc, char *argv[])
{
int sockfd, recvbytes;
char rcv_buf[MAXDATASIZE]; /*./client 127.0.0.1 hello */
char snd_buf[MAXDATASIZE];
struct hostent *host; /* struct hostent
* {
* char *h_name; // general hostname
* char **h_aliases; // hostname's alias
* int h_addrtype; // AF_INET
* int h_length;
* char **h_addr_list;
* };
*/
struct sockaddr_in server_addr;
int flags;
int addr_len;
if (argc < 3)
{
printf("Usage:%s [ip address] [any string]\n", argv[0]);
return 1;
}
*snd_buf = '\0';
strcat(snd_buf, argv[2]);
if ((sockfd = socket(AF_INET, SOCK_STREAM, 0)) == -1)
{
perror("socket:");
exit(1);
}
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(SERVPORT);
inet_pton(AF_INET, argv[1], &server_addr.sin_addr);
memset(&(server_addr.sin_zero), 0, 8);
addr_len = sizeof(struct sockaddr_in);
/* Setting socket to nonblock */
flags = fcntl(sockfd, F_GETFL, 0);
fcntl(sockfd, flags|O_NONBLOCK);
/* create the connection by socket
* means that connect "sockfd" to "server_addr"
* 同步阻塞模式
*/
if (connect(sockfd, (struct sockaddr *)&server_addr, sizeof(struct sockaddr)) == -1)
{
perror("connect");
exit(1);
}
/* 同步非阻塞模式 */
while (send(sockfd, snd_buf, sizeof(snd_buf), MSG_DONTWAIT) == -1)
{
sleep(10);
printf("sleep\n");
}
printf("send:%s\n", snd_buf);
/* 同步非阻塞模式 */
while ((recvbytes = recv(sockfd, rcv_buf, MAXDATASIZE, MSG_DONTWAIT)) == -1)
{
sleep(10);
printf("sleep\n");
}
rcv_buf[recvbytes] = '\0';
printf("recv:%s\n", rcv_buf);
close(sockfd);
return 0;
}
|
这种模式在没有数据可以接收时,可以进行其他的一些操作,
比如有多个socket时,可以去查看其他socket有没有可以接收的数据;
实际应用中,这种I/O模型的直接使用并不常见,因为它需要不停的查询,
而这些查询大部分会是无必要的调用,白白浪费了系统资源;
非阻塞I/O应该算是一个铺垫,为I/O复用和信号驱动奠定了非阻塞使用的基础。
我们可以使用 fcntl(fd, F_SETFL, flag | O_NONBLOCK);
将套接字标志变成非阻塞,调用recv,
如果设备暂时没有数据可读就返回-1,同时置errno为EWOULDBLOCK(或者EAGAIN,这两个宏定义的值相同),
表示本来应该阻塞在这里(would block,虚拟语气),事实上并没有阻塞而是直接返回错误,调用者应该试着再读一次(again)。
这种行为方式称为轮询(Poll),调用者只是查询一下,而不是阻塞在这里死等,这样可以同时监视多个设备:
while(1)
{
非阻塞read(设备1);
if(设备1有数据到达)
处理数据;
非阻塞read(设备2);
if(设备2有数据到达)
处理数据;
…………………………
}
如果read(设备1)是阻塞的,那么只要设备1没有数据到达就会一直阻塞在设备1的read调用上,
即使设备2有数据到达也不能处理,使用非阻塞I/O就可以避免设备2得不到及时处理。
非阻塞I/O有一个缺点,如果所有设备都一直没有数据到达,调用者需要反复查询做无用功,如果阻塞在那里,
操作系统可以调度别的进程执行,就不会做无用功了,在实际应用中非阻塞I/O模型比较少用
三、I/O 复用(异步阻塞)模式
频繁地去收发室对老陈来说太累了,在间隔的时间内能做的事也很少,而且取到信的效率也很低.
于是,老陈向小区物业提了建议;
小区物业改进了他们的信箱系统:
住户先向小区物业注册,之后小区物业会在已注册的住户的家中添加一个提醒装置,
每当有注册住房的新的信件来临,此装置会发出 “新信件到达”声,
提醒老陈去看是不是自己的信到了。
这就是异步阻塞模型;
在这种模型中,配置的是非阻塞 I/O,然后使用阻塞 select 系统调用来确定一个 I/O 描述符何时有操作。
使 select 调用非常有趣的是它可以用来为多个描述符提供通知,而不仅仅为一个描述符提供通知。
对于每个提示符来说,我们可以请求这个描述符可以写数据、有读数据可用以及是否发生错误的通知
I/O复用模型能让一个或多个socket可读或可写准备好时,应用能被通知到;
I/O复用模型早期用select实现,它的工作流程如下图:

用select来管理多个I/O,当没有数据时select阻塞,如果在超时时间内数据到来则select返回,
再调用recv进行数据的复制,recv返回后处理数据。
下面的C语言实现的例子,它从网络上接受数据写入一个文件中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
|
/*
* \brief
* tcp client
*/
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#define SERVPORT 8080
#define MAXDATASIZE 100
#define TFILE "data_from_socket.txt"
int main(int argc, char *argv[])
{
int sockfd, recvbytes;
char rcv_buf[MAXDATASIZE]; /*./client 127.0.0.1 hello */
char snd_buf[MAXDATASIZE];
struct hostent *host; /* struct hostent
* {
* char *h_name; // general hostname
* char **h_aliases; // hostname's alias
* int h_addrtype; // AF_INET
* int h_length;
* char **h_addr_list;
* };
*/
struct sockaddr_in server_addr;
/* */
fd_set readset, writeset;
int check_timeval = 1;
struct timeval timeout={check_timeval,0}; //阻塞式select, 等待1秒,1秒轮询
int maxfd;
int fp;
int cir_count = 0;
int ret;
if (argc < 3)
{
printf("Usage:%s [ip address] [any string]\n", argv[0]);
return 1;
}
*snd_buf = '\0';
strcat(snd_buf, argv[2]);
if ((fp = open(TFILE,O_WRONLY)) < 0) //不是用fopen
{
perror("fopen:");
exit(1);
}
if ((sockfd = socket(AF_INET, SOCK_STREAM, 0)) == -1)
{
perror("socket:");
exit(1);
}
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(SERVPORT);
inet_pton(AF_INET, argv[1], &server_addr.sin_addr);
memset(&(server_addr.sin_zero), 0, 8);
/* create the connection by socket
* means that connect "sockfd" to "server_addr"
*/
if (connect(sockfd, (struct sockaddr *)&server_addr, sizeof(struct sockaddr)) == -1)
{
perror("connect");
exit(1);
}
/**/
if (send(sockfd, snd_buf, sizeof(snd_buf), 0) == -1)
{
perror("send:");
exit(1);
}
printf("send:%s\n", snd_buf);
while (1)
{
FD_ZERO(&readset); //每次循环都要清空集合,否则不能检测描述符变化
FD_SET(sockfd, &readset); //添加描述符
FD_ZERO(&writeset);
FD_SET(fp, &writeset);
maxfd = sockfd > fp ? (sockfd+1) : (fp+1); //描述符最大值加1
ret = select(maxfd, &readset, NULL, NULL, NULL); // 阻塞模式
switch( ret)
{
case -1:
exit(-1);
break;
case 0:
break;
default:
if (FD_ISSET(sockfd, &readset)) //测试sock是否可读,即是否网络上有数据
{
recvbytes = recv(sockfd, rcv_buf, MAXDATASIZE, MSG_DONTWAIT);
rcv_buf[recvbytes] = '\0';
printf("recv:%s\n", rcv_buf);
if (FD_ISSET(fp, &writeset))
{
write(fp, rcv_buf, strlen(rcv_buf)); // 不是用fwrite
}
goto end;
}
}
cir_count++;
printf("CNT : %d \n",cir_count);
}
end:
close(fp);
close(sockfd);
return 0;
}
|
perl实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
#! /usr/bin/perl
###############################################################################
# \File
# tcp_client.pl
# \Descript
# send message to server
###############################################################################
use IO::Socket;
use IO::Select;
#hash to install IP Port
%srv_info =(
#"srv_ip" => "61.184.93.197",
"srv_ip" => "192.168.1.73",
"srv_port"=> "8080",
);
my $srv_addr = $srv_info{"srv_ip"};
my $srv_port = $srv_info{"srv_port"};
my $sock = IO::Socket::INET->new(
PeerAddr => "$srv_addr",
PeerPort => "$srv_port",
Type => SOCK_STREAM,
Blocking => 1,
# Timeout => 5,
Proto => "tcp")
or die "Can not create socket connect. $@";
$sock->send("Hello server!\n", 0) or warn "send failed: $!, $@";
$sock->autoflush(1);
my $sel = IO::Select->new($sock);
while(my @ready = $sel->can_read)
{
foreach my $fh(@ready)
{
if($fh == $sock)
{
while()
{
print $_;
}
$sel->remove($fh);
close $fh;
}
}
}
$sock->close();
|
四、信号驱动 I/O 模型
老陈接收到新的信件后,一般的程序是:
打开信封—-掏出信纸 —-阅读信件—-回复信件 ……
为了进一步减轻用户负担,小区物业又开发了一种新的技术:
住户只要告诉小区物业对信件的操作步骤,小区物业信箱将按照这些步骤去处理信件,
不再需要用户亲自拆信 /阅读/回复了!
这就是信号驱动I/O模型
我们也可以用信号,让内核在描述字就绪时发送SIGIO信号通知我们。
首先开启套接口的信号驱动 I/O功能,并通过sigaction系统调用安装一个信号处理函数。
该系统调用将立即返回,我们的进程继续工作,也就是说没被阻塞。
当数据报准备好读取时,内核就为该进程产生一个SIGIO信号,
我们随后既可以在信号处理函数中调用recvfrom读取数据报,并通知主循环数据已准备好待处理,
也可以立即通知主循环,让它读取数据报。

无论如何处理SIGIO信号,这种模型的优势在于等待数据报到达期间,进程不被阻塞,主循环可以继续执行,
只要不时地等待来自信号处理函数的通知:既可以是数据已准备好被处理,也可以是数据报已准备好被读取。
五、异步非阻塞模式
linux下的asynchronous IO其实用得很少。
与前面的信号驱动模型的主要区别在于:信号驱动 I/O是由内核通知我们何时可以启动一个 I/O操作,
而异步 I/O模型是由内核通知我们 I/O操作何时完成 。
先看一下它的流程:
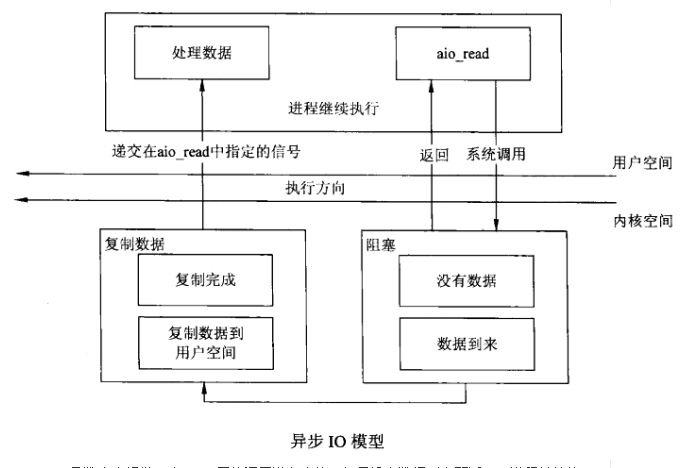
这就是异步非阻塞模式
以read系统调用为例
steps:
a. 调用read;
b. read请求会立即返回,说明请求已经成功发起了。
c. 在后台完成读操作这段时间内,应用程序可以执行其他处理操作。
d. 当 read 的响应到达时,就会产生一个信号或执行一个基于线程的回调函数来完成这次 I/O 处理过程。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
|
/*
* \brief
* tcp client
*/
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#define SERVPORT 8080
#define MAXDATASIZE 100
#define TFILE "data_from_socket.txt"
int main(int argc, char *argv[])
{
int sockfd, recvbytes;
char rcv_buf[MAXDATASIZE]; /*./client 127.0.0.1 hello */
char snd_buf[MAXDATASIZE];
struct hostent *host; /* struct hostent
* {
* char *h_name; // general hostname
* char **h_aliases; // hostname's alias
* int h_addrtype; // AF_INET
* int h_length;
* char **h_addr_list;
* };
*/
struct sockaddr_in server_addr;
/* */
fd_set readset, writeset;
int check_timeval = 1;
struct timeval timeout={check_timeval,0}; //阻塞式select, 等待1秒,1秒轮询
int maxfd;
int fp;
int cir_count = 0;
int ret;
if (argc < 3)
{
printf("Usage:%s [ip address] [any string]\n", argv[0]);
return 1;
}
*snd_buf = '\0';
strcat(snd_buf, argv[2]);
if ((fp = open(TFILE,O_WRONLY)) < 0) //不是用fopen
{
perror("fopen:");
exit(1);
}
if ((sockfd = socket(AF_INET, SOCK_STREAM, 0)) == -1)
{
perror("socket:");
exit(1);
}
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(SERVPORT);
inet_pton(AF_INET, argv[1], &server_addr.sin_addr);
memset(&(server_addr.sin_zero), 0, 8);
/* create the connection by socket
* means that connect "sockfd" to "server_addr"
*/
if (connect(sockfd, (struct sockaddr *)&server_addr, sizeof(struct sockaddr)) == -1)
{
perror("connect");
exit(1);
}
/**/
if (send(sockfd, snd_buf, sizeof(snd_buf), 0) == -1)
{
perror("send:");
exit(1);
}
printf("send:%s\n", snd_buf);
while (1)
{
FD_ZERO(&readset); //每次循环都要清空集合,否则不能检测描述符变化
FD_SET(sockfd, &readset); //添加描述符
FD_ZERO(&writeset);
FD_SET(fp, &writeset);
maxfd = sockfd > fp ? (sockfd+1) : (fp+1); //描述符最大值加1
ret = select(maxfd, &readset, NULL, NULL, &timeout); // 非阻塞模式
switch( ret)
{
case -1:
exit(-1);
break;
case 0:
break;
default:
if (FD_ISSET(sockfd, &readset)) //测试sock是否可读,即是否网络上有数据
{
recvbytes = recv(sockfd, rcv_buf, MAXDATASIZE, MSG_DONTWAIT);
rcv_buf[recvbytes] = '\0';
printf("recv:%s\n", rcv_buf);
if (FD_ISSET(fp, &writeset))
{
write(fp, rcv_buf, strlen(rcv_buf)); // 不是用fwrite
}
goto end;
}
}
timeout.tv_sec = check_timeval; // 必须重新设置,因为超时时间到后会将其置零
cir_count++;
printf("CNT : %d \n",cir_count);
}
end:
close(fp);
close(sockfd);
return 0;
}
|
server端程序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
|
/*
* \brief
* tcp server
*/
#include
#include
#include
#include
#include
#include
#include
#define SERVPORT 8080
#define BACKLOG 10 // max numbef of client connection
#define MAXDATASIZE 100
int main(char argc, char *argv[])
{
int sockfd, client_fd, addr_size, recvbytes;
char rcv_buf[MAXDATASIZE], snd_buf[MAXDATASIZE];
char* val;
struct sockaddr_in server_addr;
struct sockaddr_in client_addr;
int bReuseaddr = 1;
char IPdotdec[20];
/* create a new socket and regiter it to os .
* SOCK_STREAM means that supply tcp service,
* and must connect() before data transfort.
*/
if ((sockfd = socket(AF_INET, SOCK_STREAM, 0)) == -1)
{
perror("socket:");
exit(1);
}
/* setting server's socket */
server_addr.sin_family = AF_INET; // IPv4 network protocol
server_addr.sin_port = htons(SERVPORT);
server_addr.sin_addr.s_addr = INADDR_ANY; // auto IP detect
memset(&(server_addr.sin_zero),0, 8);
setsockopt(sockfd, SOL_SOCKET, SO_REUSEADDR, (const char*)&bReuseaddr, sizeof(int));
if (bind(sockfd, (struct sockaddr*)&server_addr, sizeof(struct sockaddr))== -1)
{
perror("bind:");
exit(1);
}
/*
* watting for connection ,
* and server permit to recive the requestion from sockfd
*/
if (listen(sockfd, BACKLOG) == -1) // BACKLOG assign thd max number of connection
{
perror("listen:");
exit(1);
}
while(1)
{
addr_size = sizeof(struct sockaddr_in);
/*
* accept the sockfd's connection,
* return an new socket and assign far host to client_addr
*/
printf("watting for connect...\n");
if ((client_fd = accept(sockfd, (struct sockaddr *)&client_addr, &addr_size)) == -1)
{
/* Nonblocking mode */
perror("accept:");
continue;
}
/* network-digital to ip address */
inet_ntop(AF_INET, (void*)&client_addr, IPdotdec, 16);
printf("connetion from:%d : %s\n",client_addr.sin_addr, IPdotdec);
//if (!fork())
{
/* child process handle with the client connection */
/* recive the client's data by client_fd */
if ((recvbytes = recv(client_fd, rcv_buf, MAXDATASIZE, 0)) == -1)
{
perror("recv:");
exit(1);
}
rcv_buf[recvbytes]='\0';
printf("recv:%s\n", rcv_buf);
*snd_buf='\0';
strcat(snd_buf, "welcome");
sleep(3);
/* send the message to far-hosts by client_fd */
if (send(client_fd, snd_buf, strlen(snd_buf), 0) == -1)
{
perror("send:");
exit(1);
}
printf("send:%s\n", snd_buf);
close(client_fd);
//exit(1);
}
//close(client_fd);
}
return 0;
}
|
用户进程发起read操作之后,立刻就可以开始去做其它的事。
而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,
所以不会对用户进程产生任何block。
然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,
kernel会给用户进程发送一个signal,告诉它read操作完成了。
六、总结
到目前为止,已经将四个IO Model都介绍完了。
现在回过头来回答两个问题:
- blocking和non-blocking的区别在哪?
- synchronous IO和asynchronous IO的区别在哪。
先回答最简单的这个:blocking vs non-blocking。
前面的介绍中其实已经很明确的说明了这两者的区别。
- 调用blocking IO会一直block住对应的进程直到操作完成,
- 而non-blocking IO在kernel还在准备数据的情况下会立刻返回。
在说明synchronous IO和asynchronous IO的区别之前,需要先给出两者的定义。
Stevens给出的定义(其实是POSIX的定义)是这样子的:
- A synchronous I/O operation causes the requesting process to be blocked until that I/O operation completes;
- An asynchronous I/O operation does not cause the requesting process to be blocked;
两者的区别就在于:
synchronous IO做”IO operation”的时候会将process阻塞。
按照这个定义,之前所述的blocking IO,non-blocking IO,IO multiplexing都属于synchronous IO。
有人可能会说,non-blocking IO并没有被block啊。这里有个非常“狡猾”的地方,
- 定义中所指的”IO operation”是指真实的IO操作,就是例子中的recvfrom这个system call。
non-blocking IO在执行recvfrom这个system call的时候,如果kernel的数据没有准备好,这时候不会block进程。
但是,当kernel中数据准备好的时候,recvfrom会将数据从kernel拷贝到用户内存中,
这个时候进程是被block了,在这段时间内,进程是被block的。 - 而asynchronous IO则不一样,当进程发起IO 操作之后,就直接返回再也不理睬了,
直到kernel发送一个信号,告诉进程说IO完成。在这整个过程中,进程完全没有被block。
各个IO Model的比较如图所示:

经过上面的介绍,会发现non-blocking IO和asynchronous IO的区别还是很明显的:
. 在non-blocking IO中,虽然进程大部分时间都不会被block,但是它仍然要求进程去主动的check,
并且当数据准备完成以后,也需要进程主动的再次调用recvfrom来将数据拷贝到用户内存。
. 而asynchronous IO则完全不同。它就像是用户进程将整个IO操作交给了他人(kernel)完成,
然后他人做完后发信号通知。在此期间,用户进程不需要去检查IO操作的状态,也不需要主动的去拷贝数据。
最后,再举几个不是很恰当的例子来说明这五个IO Model:
有A,B,C,D,E五个人钓鱼:
. A用的是最老式的鱼竿,所以呢,得一直守着,等到鱼上钩了再拉杆;
. B的鱼竿有个功能,能够显示是否有鱼上钩,所以呢,B就和旁边的MM聊天,
隔会再看看有没有鱼上钩,有的话就迅速拉杆;
. C用的鱼竿和B差不多,但他想了一个好办法,就是同时放好几根鱼竿,然后守在旁边,
一旦有显示说鱼上钩了,它就将对应的鱼竿拉起来;
. D是个有钱人,他没耐心等, 但是又喜欢钓上鱼的快感,所以雇了个人,一旦那个人发现有鱼上钩,
就会通知D过来把鱼钓上来;
. E也是个有钱人,干脆雇了一个人帮他钓鱼,一旦那个人把鱼钓上来了,就给E发个短信。 |






