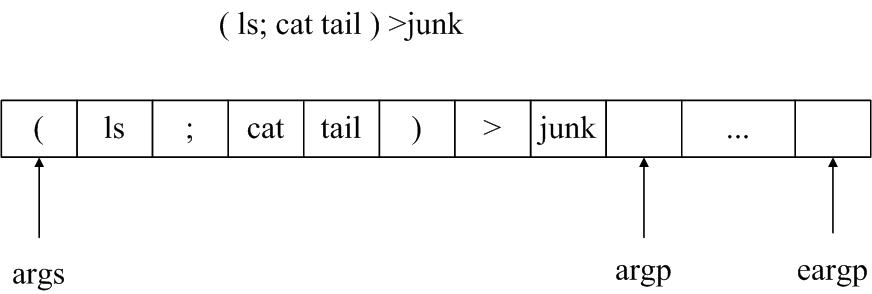
词法扫描(lexical scanning)经过预处理后的字符序列将被切割成为一系列词法记号(token),安置在token列表中,扫描器将对以下几类字符做如下处理。
举一个例子,当我们输入命令”(ls; cat tail) >junk”,那么token列表映像将是这样的:
语法分析(syntax parser)语法分析就是将token列表中的元素作为表达式(expression)并以节点为单位构建语法树,简单命令 是一个表达式,而复合命令以及命令序列是多个表达式的组合。Thompson Shell中以简单数组作为语法树的容器,实际上这是结构体的一种变形,只不过每个成员字段大小都一样(都是sizeof int)而已。一个语法树节点最多有6个字段(大小根据类型可变),分别是
语法树节点生成顺序根据token列表中每个元素的优先级(priority)而定,首先遍历整个列表,找到优先级最高的token作为根节点,再分别生成左右子树,这是一种最简单的自顶向下(top-down)解决方案。各个token优先级视DTYP字段而定
语法树的构建过程中还使用了一种基于“有限状态机(finite-state machine)”的动态规划算 法,其实现是将整个逻辑流程划分为四个状态:syntax、syn1、syn2、syn3,对应于上面token优先级,程序在每个状态下都生成一个相应 类型的节点,同时还生成四种策略,以决议下一步将转移到何种状态(根据优先级搜索对应的token)。这个四种策略分别是
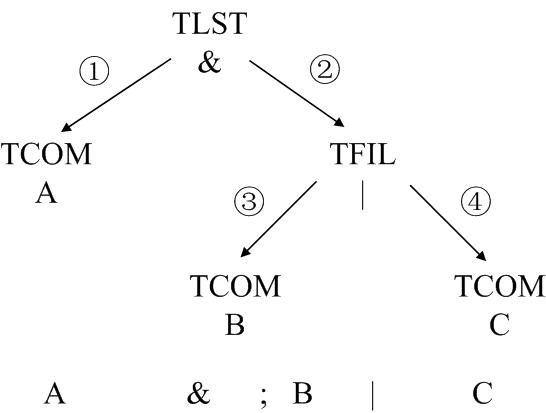
当我们遍历完整个token列表后,程序总是能返回最初的调用点,即根节点上,从而生成一棵完整的语法树。这种算法的好处是程序员不必关注具体实现的每个细枝末节,只要关注相应的状态并制定对应的转移策略即可。还值得一提的是每个转移策略都是发生在赋值语句或返回语句上,并使用函数实参保存临时变量,这样就避免了调用次数过多导致堆栈溢出。 依旧举两个个例子,比如命令”A & ; B | C”对应的语法树
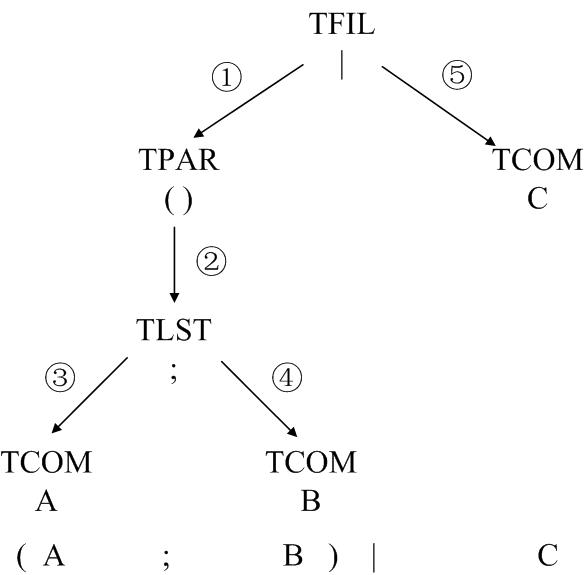
命令”(A ; B) | C”对应的语法树:
语义分析(Semantic Analyzer)语法分析仅仅停留在token表达式合法性层面上,它并不知道该表达式是否有意义,比如哪些命令是要后台运行,哪些命令的I/O被重定向到管道线上,通配符该如何扩展等等,这时候要靠语义分析了。这里的“语义”体现在对特殊字符的动态处理以及语法树节点的字段设置,根据上下文(context)而 定。比如对于元字符’>’,我们要判断输出重定向到哪个文件,是截断还是追加。对于通配符’?'、’*'和’[...]‘,我们要决定对哪些字符进 行扩展,这些在/etc/glob中专门处理。对于语法树节点,除了自身固有属性之外,还需要继承上层节点的属性,以及下推属性到下层子树节点,下面列了 一张表格说明。
|